Nous réalisons ci-dessous deux tests supplémentaires pour démontrer que lorsqu’il s’agit d’examiner les données a posteriori, nous avons plusieurs options à notre disposition. Le premier est le test de Bonferroni, qui maintient l’erreur de type I globale à un niveau nominal en divisant le seuil de signification souhaité par le nombre de comparaisons effectuées.
Par exemple, si nous voulons faire 3 comparaisons tout en gardant un alpha global égal à 0,05, nous pouvons exécuter chaque comparaison à 0,05 / 3 = 0,0167.
Le test de Bonferroni peut être utilisé comme comparaison a priori ou post hoc, mais il faut noter qu’il est généralement préférable lorsqu’il y a un petit nombre de moyennes (par exemple 3 ou 4).
Si vous avez de nombreuses moyennes dans votre ANOVA, alors diviser alpha par un grand nombre donnerait à chaque test une puissance très faible.
Par exemple, si vous avez 10 comparaisons à faire, alors 0,05 / 10 = 0,005, ce qui est un seuil de signification assez difficile à rejeter pour une hypothèse nulle moyenne.
Nous réalisons aussi le test de Scheffé, qui est un test très conservateur. Si vous parvenez à rejeter l’hypothèse nulle avec le test de Scheffé, vous pouvez avoir une grande confiance qu’une véritable différence existe.
Comparaisons multiples
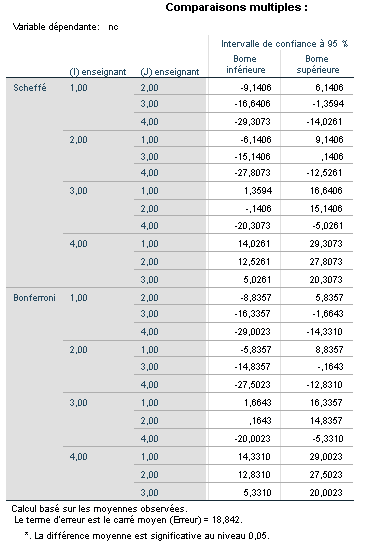
Variable dépendante : ac
Tableau des différences moyennes, erreurs standards, intervalles de confiance à 95 % et significations pour les comparaisons multiples via Scheffé et Bonferroni.
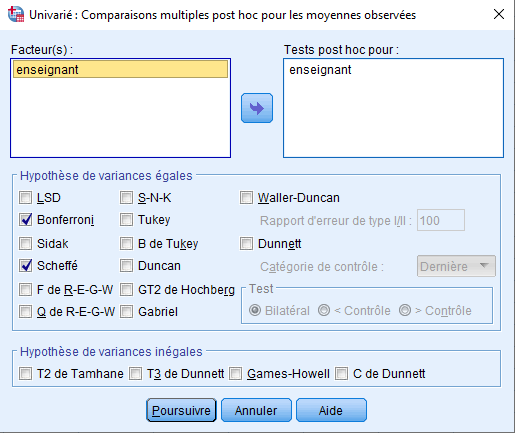
Comme nous l’avons fait lors du test de Tukey, nous avons déplacé enseugnment de « Facteur(s) » vers la partie droite, en sélectionnant cette fois Bonferroni et Scheffé comme nos tests post hoc souhaités.
Les différences de moyennes sont interprétées de la même manière qu’avec le test de Tukey ; cependant, nous constatons que le test de Scheffé ne rejette plus l’hypothèse nulle dans la comparaison entre les niveaux 2 et 3 de teach (p = 0,056), alors que le test de Tukey l’avait fait (p = 0,033). Cela s’explique par le fait que, comme mentionné précédemment, le test de Scheffé est beaucoup plus strict et conservateur que celui de Tukey.
Quant au test de Bonferroni, il rejette également l’hypothèse nulle entre teach 2 et teach 3, mais avec une valeur p de 0,043, comparée à 0,033 pour Tukey. Ces différences de valeurs p illustrent bien les divergences de résultats qui peuvent apparaître selon le test post hoc choisi.
SPSS propose de nombreuses autres options de tests post hoc. Howell (2002) offre un excellent résumé de ces procédures et peut être consulté pour plus d’informations.
Le point le plus important pour le moment est que vous compreniez qu’un test post hoc peut être plus conservateur ou plus libéral, et qu’en cas de doute, si vous rapportez généralement les résultats du test de Tukey, vous restez généralement sur un terrain sûr en termes de crédibilité statistique.
Tracer les différences de moyennes
Souvenez-vous que nous avions demandé une courbe de profil des moyennes, qui apparaît ci-dessous :
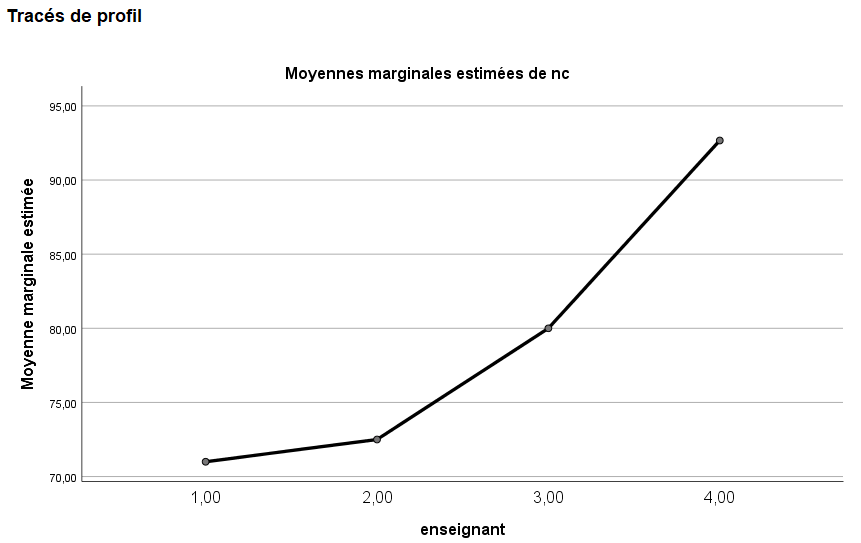
Le graphique confirme qu’en passant du niveau 1 au niveau 4 de teach, la performance moyenne augmente.
On peut aussi y voir pourquoi les tests post hoc n’ont pas trouvé de différences entre, par exemple, teach 1 et teach 2 (les moyennes sont très proches sur le graphique), mais ont détecté une différence significative entre d’autres niveaux (par exemple 1 vs 4, 2 vs 4, etc.).
Rappelons également que nous avons effectué une ANOVA à effets fixes, et que dans ce type d’analyse, le chercheur souhaite uniquement généraliser les conclusions aux niveaux spécifiques étudiés dans l’analyse.
Ainsi, pour nos données, le fait d’avoir trouvé une différence significative globale entre les moyennes dans l’ANOVA suggère qu’il existe des différences spécifiques entre ces enseignants en particulier.
Si nous avions voulu conclure qu’il existe des différences entre ces enseignants ou d’autres que nous aurions échantillonnés au hasard, nous aurions dû effectuer une ANOVA à effets aléatoires, un sujet que nous abordons brièvement maintenant.