Étant donné que la majorité des régressions que vous conduirez seront probablement des régressions multiples, nous consacrons la majeure partie de ce chapitre à l’interprétation du modèle de régression multiple. Cependant, pour commencer, nous présentons un modèle de régression simple et nous concentrons sur l’interprétation des coefficients de ce modèle. Régressons la variable « verbal » sur la variable « quantitative » : ANALYSE – REGRESSION – LINEARE.
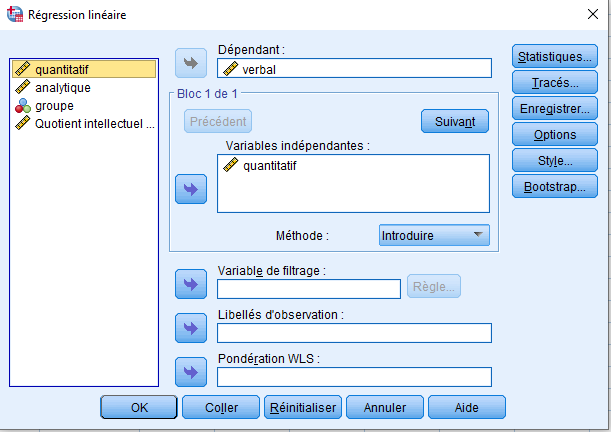

Nous sélectionnerons davantage d’options lorsque nous aborderons la régression multiple, mais pour l’instant, examinons les résultats de ce modèle simple :

Pour le modèle de régression simple, la valeur de R (0.808) est égale à la corrélation bivariée entre « quantitatif » et « verbal ». Comme nous le verrons, dans le modèle de régression multiple, R sera défini de manière plus complexe et représentera la corrélation des prédicteurs (au pluriel) avec la variable réponse. Le R2 de 0.653 est le carré de R et représente la proportion de variance de « verbal » expliquée par « quantitatif ».
Pour nos données, le R2 ajusté est donné par :
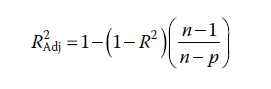
où est le nombre d’observations et p est le nombre de paramètres estimés dans le modèle (y compris l’ordonnée à l’origine). Le rôle de R2Aj est de fournir une estimation plus prudente de la vraie valeur de R2Aj dans la population, car il « pénalise » en quelque sorte l’ajout de paramètres non pertinents. Ainsi, R2Aj est généralement inférieur à R2. Pour nos données, le R2 ajusté de 0.641 est légèrement inférieur au R2 de 0.653. Le choix de rapporter la valeur ajustée ou non dans vos résultats est souvent une question de préférence. L’erreur standard de l’estimation est la racine carrée de la moyenne des résidus (MS Residual) de l’ANOVA associée à la régression, qui montre comment la variance a été partitionnée :
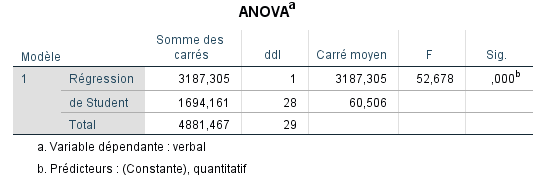
Remarquez que la valeur de l’erreur standard de l’estimation est égale à la racine carrée de 60.506, la valeur de MS Residual. Nous discuterons plus en détail le contenu du tableau ANOVA lorsque nous aborderons le modèle de régression multiple complet. Pour l’instant, nous pouvons observer que nous avons obtenu une statistique F de 52.678, qui est statistiquement significative (p=0.000), indiquant que la prédiction de « verbal » à l’aide de « quantitatif » est meilleure que sans « quantitatif ». Nous pouvons également voir comment R2 a été calculé par le rapport SS Régression / SS Total (soit 3187.305 / 4881.467 = 0.653). Les degrés de liberté pour la régression correspondent au nombre de prédicteurs dans le modèle, qui est ici de 1. Les degrés de liberté résiduels sont égaux à n−k−1=30−1−1=28 (où k est le nombre de prédicteurs, ici égal à 1).
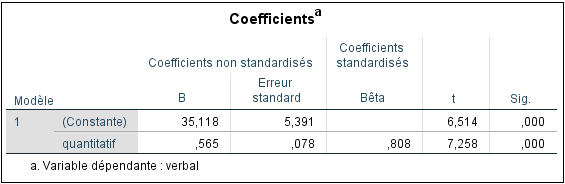
SPSS nous fournit les coefficients du modèle. La valeur de la constante est la valeur prédite lorsque « quant » est égal à 0. L’équation de régression estimée est :
Verbal=35.118+0.565(quantitatif).
L’ordonnée à l’origine est calculée par :
![]()
où aY⋅X est l’ordonnée à l’origine de Y régressé sur X et bY⋅X est la pente de Y régressé sur X. Lorsque « quantitatif » = 0, nous avons :
Verbal=35.118+0.565(0)=35.118+0=35.118
Le coefficient pour « quantitatif » est de 0.565 et s’interprète comme suit : pour une augmentation d’une unité de « quantitatif », nous pouvons nous attendre, en moyenne, à une augmentation de 0.565 unités de « verbal ». Ce coefficient de 0.565 est la pente de la régression de « verbal » sur « quantitatif » et est calculé par :
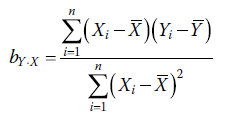
Nous voyons que la pente compare la somme des produits croisés au numérateur avec la somme des carrés pour Xi au dénominateur. Généralement, nous ne nous intéressons pas autant à la valeur de l’ordonnée à l’origine, ni à son test de significativité. Notre attention se porte davantage sur la pente, car c’est elle qui nous renseigne sur la capacité prédictive de notre variable explicative.
SPSS indique les erreurs standard (Std. Error) pour l’ordonnée à l’origine et la pente, utilisées pour calculer les tests t associés à chaque paramètre estimé. Par exemple, la statistique t de 6.514 pour la constante est calculée par 35.118 / 5.391, tandis que celle de 7.258 pour « quantitatif » est obtenue par 0.565 / 0.078. L’hypothèse nulle testée pour la constante et la pente est qu’elles sont toutes deux égales à 0. Pour la pente, cela revient à dire que « quantitatif » n’apporte aucune puissance prédictive supplémentaire par rapport à la simple prédiction de la moyenne de « verbal ». Comme p=0.000, nous avons des preuves inférentielles suggérant que la pente dans la population n’est pas nulle. En effet, le R2 de 0.653 indique qu’environ 65 % de la variance de « verbal » est expliquée par « quantitatif ».
Bien sûr, le modèle ne sera pas parfait, et nous observerons des erreurs par rapport à la droite de régression ajustée. Un résidu est la différence entre la valeur observée et la valeur prédite, soit yi−yi′. Les résidus sont importants à examiner après l’ajustement du modèle, non seulement pour évaluer la qualité globale de l’ajustement, mais aussi pour valider les hypothèses sous-jacentes. Nous réservons cette discussion pour le modèle de régression multiple complet, que nous aborderons ensuite.