À titre d’exemple simple de régression linéaire, rappelons nos données de QI mentionnées précédemment :
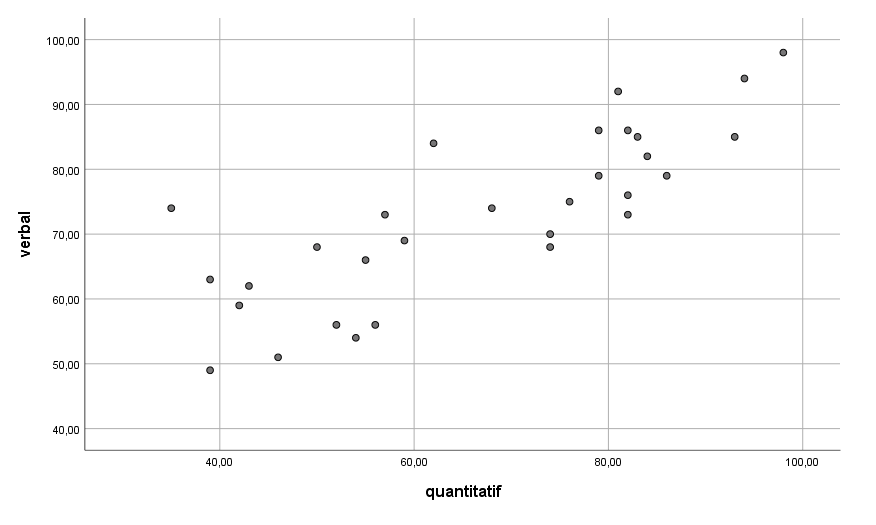
Examinons un nuage de points verbal en fonction du quantitatif. Nous constatons que la relation est approximativement linéaire. Malgré la dispersion des points de données, nous pourrions ajuster une droite aux données afin de prédire les valeurs du verbal à partir des valeurs du quantitatif. Nous ajustons ci-dessous une telle droite, appelée droite des moindres carrés :
La droite de régression des moindres carrés de la population est donnée par : yi=α+βxi+εi
où α est l’ordonnée à l’origine de la population et β est la pente de la population. Les valeurs de εᵢ sont les erreurs de prédiction. Bien entendu, nous ne connaîtrons généralement pas les valeurs de α et β dans la population et devrons donc les estimer à l’aide des données de l’échantillon. La droite des moindres carrés est ajustée de manière à ce que, lorsque nous l’utilisons pour prédire le score verbal à partir du score quantitatif, nos erreurs de prédiction soient, en moyenne, plus faibles que si nous avions ajusté une autre droite. Une erreur de prédiction est une déviation de la forme :
ei=yi−y’i.
où yᵢ sont les valeurs observées du verbal et ŷᵢ sont les valeurs prédites. La régression des moindres carrés garantit que la somme des carrés de ces erreurs est minimale (c’est-à-dire la plus petite possible comparée à tout autre ajustement de droite) :
![]()
Si le modèle de population était une régression linéaire multiple, nous pourrions avoir une seconde variable prédictive :
yi=a+b1x1i+b2x2i+εi
et la fonction des moindres carrés viserait alors à minimiser ce qui suit :
![]()
Notez que, que le modèle soit simple ou multiple, le concept reste le même. On ajuste une fonction des moindres carrés de manière à minimiser la somme des carrés des erreurs autour de la fonction.