Rappelons le modèle de régression multiple évoqué précédemment :
yi=α+β1 x1i+β2 x2i+εi.
Comme le modèle de régression linéaire simple, le modèle ci-dessus vise à faire des prédictions de la variable réponse, mais cette fois, au lieu d’utiliser uniquement un seul prédicteur xi, nous incluons maintenant un deuxième prédicteur x2. Nous n’avons pas besoin de nous arrêter là ; nous pouvons théoriquement inclure beaucoup plus de prédicteurs, de sorte que la forme générale du modèle devient, pour k prédicteurs :
yi=α+β1 x1i+β2 x2i+.⋯
Bien que l’objectif de la régression multiple soit le même que celui de la régression simple, c’est-à-dire faire des prédictions de la réponse, traiter plusieurs dimensions simultanément devient beaucoup plus complexe et nécessite des matrices pour illustrer les calculs. Bien que nous utiliserons des matrices plus tard dans le livre lorsque nous aborderons les techniques multivariées, pour l’instant, nous reportons notre discussion à leur sujet et nous concentrons uniquement sur l’interprétation du modèle de régression à travers un exemple.
Nous allons maintenant démontrer comment effectuer une analyse de régression multiple complète dans SPSS et comment interpréter les résultats. Nous effectuerons notre régression multiple sur l’ensemble de données fictif suivant, tiré de Petrocelli (2003), dans lequel nous sommes intéressés par la prédiction de l’Évaluation Globale du Fonctionnement (GAF) (des scores plus élevés indiquent un meilleur fonctionnement) basée sur trois prédicteurs : l’âge, le score de dépression avant la thérapie (des scores plus élevés indiquent plus de dépression) et le nombre de séances de thérapie.
Nos données dans SPSS se présentent comme suit :
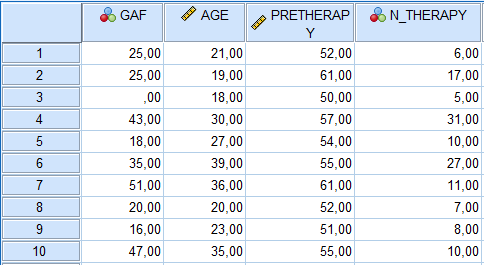
Nos variables sont définies comme suit :
-
GAF – Score d’Évaluation Globale du Fonctionnement (des scores plus élevés indiquent un meilleur fonctionnement).
-
AGE – Âge du participant en années.
-
PRETHERAPY – Score de dépression d’un participant avant la thérapie (des scores plus élevés = plus de dépression).
-
N_THERAPY – Nombre de séances de thérapie pour un participant.
Il n’y a que 10 cas par variable, mais il est néanmoins utile d’examiner leurs distributions, à la fois de manière univariée (c’est-à-dire pour chaque variable) et bivariée par paires (deux variables à la fois dans des diagrammes de dispersion), à la fois pour avoir une idée de la distribution continue des variables et aussi pour des preuves préliminaires qu’il existe des relations linéaires entre les variables. Bien que les prédicteurs dans la régression puissent représenter des groupements catégoriels (s’ils sont codés de manière appropriée), pour cette régression, nous supposerons que les prédicteurs sont continus. Cela implique que le prédicteur doit avoir une variabilité raisonnable. Les analyses exploratoires suivantes aideront à confirmer la continuité de nos variables prédictives. Rappelons également que pour la régression, la variable dépendante (ou réponse) doit être continue. Si ce n’est pas le cas, comme une variable codée binaire (par exemple, oui vs non), alors la régression multiple n’est pas la meilleure stratégie. L’analyse discriminante ou la régression logistique est plus adaptée pour les modèles avec des variables dépendantes binaires ou polytomiques. « Polytomique » signifie que la variable a plusieurs catégories.
Nous générons quelques histogrammes de nos variables :
GRAPHIQUES → DIALOGUES ANCIENS → HISTOGRAMME
Nous sélectionnons d’abord la variable GAF pour examiner son histogramme :
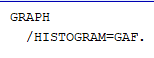
Nous déplaçons « GAF » du côté gauche vers le côté droit sous Variable. La syntaxe ci-dessus est celle qui pourrait être utilisée dans la fenêtre de syntaxe au lieu de l’interface graphique. Dans la fenêtre de syntaxe, nous entrerions :
FICHIER → NOUVEAU → SYNTAXE
Après avoir saisi la syntaxe, cliquez sur la flèche verte en haut à droite pour exécuter la syntaxe.
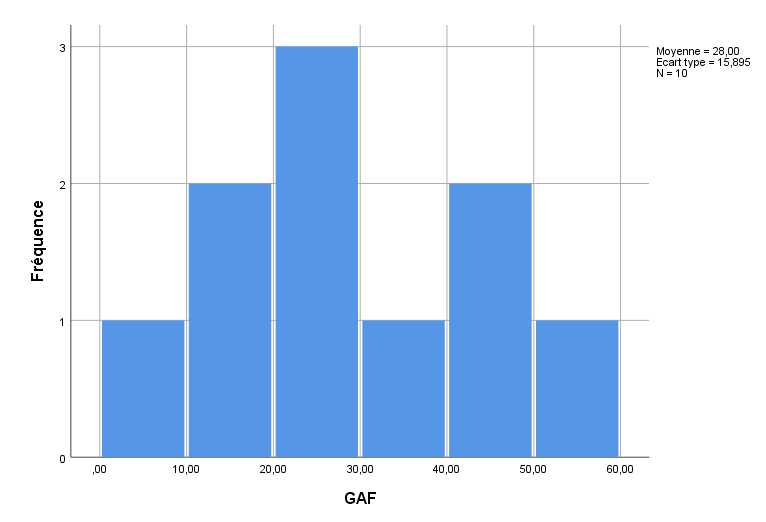
Nous remarquons (à gauche) qu’avec une moyenne égale à 28.00 et un écart type de 15.89, la variable GAF semble être quelque peu normalement distribuée dans l’échantillon. Les distributions d’échantillon des variables ne seront jamais parfaitement normales, ni n’ont besoin de l’être pour la régression. La question pour l’instant a plus à voir avec le fait que la variable a une distribution suffisante le long de l’axe des x pour la traiter comme une variable continue. Pour GAF, la variable semble relativement « bien comportée » à cet égard.
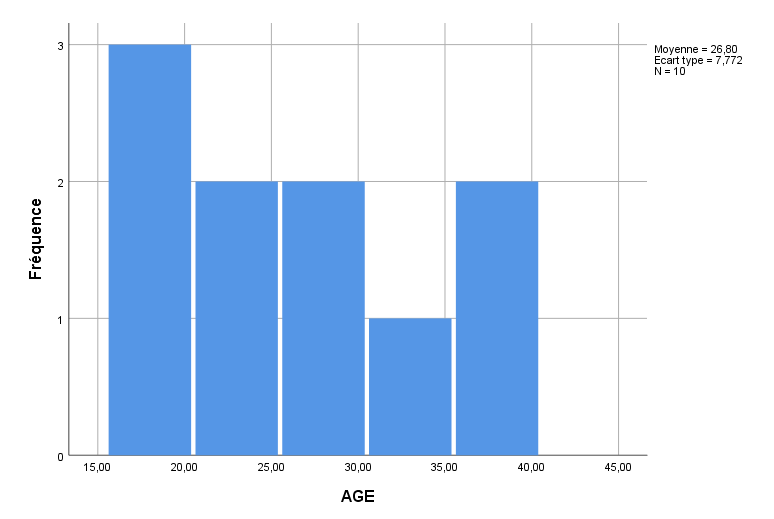
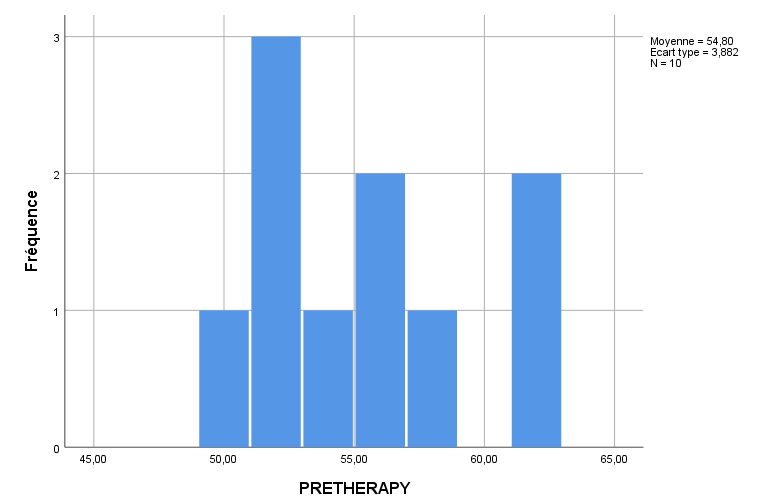
Les histogrammes des variables prédictives AGE, PRETHERAPY et N_THERAPY suivent ci-dessous :
GRAPHIQUES → DIALOGUES ANCIENS → HISTOGRAMME
GRAPH /HISTOGRAM=AGE.
GRAPH /HISTOGRAM=PRETHERAPY.
GRAPH /HISTOGRAMME=N_THERAPY.
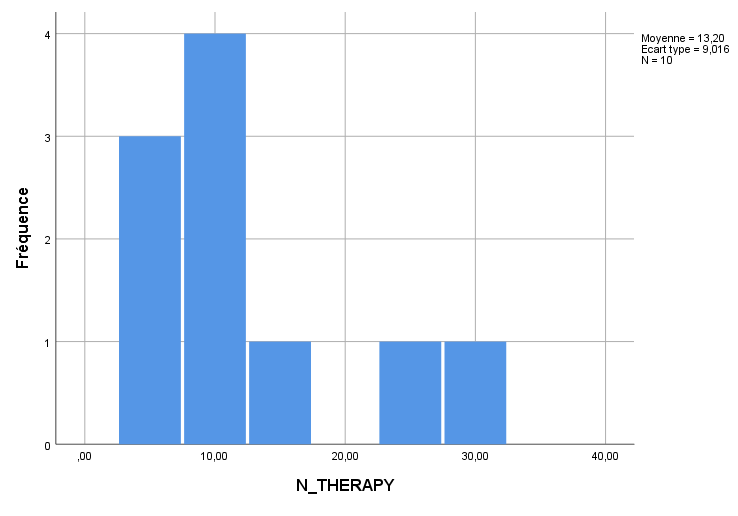
Tous les histogrammes révèlent une certaine continuité dans leurs variables respectives, suffisante pour que nous puissions procéder à la régression multiple. Rappelez-vous, ces distributions n’ont pas besoin d’être parfaitement normales pour que nous puissions continuer, ni la régression ne les exige – nous traçons simplement les distributions pour avoir une idée de la mesure dans laquelle il y a une distribution (la mesure dans laquelle les scores varient), mais le fait que ces distributions ne soient pas normalement distribuées n’est pas un problème. Une des hypothèses de la régression multiple est que les résidus (du modèle que nous allons construire) sont généralement approximativement normalement distribués, mais nous vérifierons cette hypothèse via des analyses des résidus après avoir ajusté le modèle. Les résidus sont basés sur le modèle ajusté complet, et non sur des distributions univariées considérées séparément comme ci-dessus.