Données Manquantes dans SPSS : Réfléchissez à Deux Fois Avant de Remplacer les Données !
Idéalement, lorsque vous collectez des données pour une expérience ou une étude, vous devriez pouvoir recueillir des mesures pour chaque participant, et votre fichier de données serait complet. Cependant, il arrive souvent que des données soient manquantes. Par exemple, supposons que notre ensemble de données sur le QI, au lieu d’être complet, présente quelques observations manquantes :
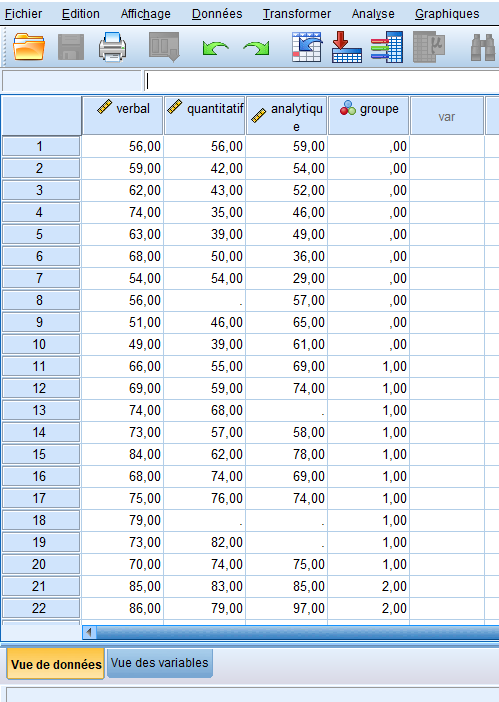
Nous pouvons constater que pour les cas 8, 13 et 18, il y a des données manquantes. SPSS offre de nombreuses fonctionnalités pour remplacer les données manquantes, mais si elles doivent être utilisées, cela doit être fait avec une extrême prudence.
Toute tentative de remplacer une donnée manquante, quelle que soit la méthode utilisée, reste une « estimation éclairée » de ce qu’aurait pu être cette donnée si le participant avait répondu ou si elle n’avait pas été perdue. L’objectif de votre investigation scientifique est de faire de la science, ce qui signifie mesurer des objets dans la nature. Dans une telle investigation, les données sont votre seul lien avec ce que vous étudiez. Remplacer une valeur manquante signifie que vous êtes prêt à « deviner » ce qu’aurait pu être l’observation, ce qui enlève son caractère de reflet direct de votre processus de mesure.
Dans certains cas, comme dans les designs longitudinaux ou à mesures répétées, éviter les données manquantes est difficile car les participants peuvent abandonner l’étude ou simplement ne pas se présenter. Cependant, cela ne signifie pas nécessairement que vous devriez automatiquement remplacer leurs valeurs. Posez-vous des questions sur vos données manquantes. Pour nos données de QI, bien que nous puissions attribuer les observations manquantes pour les cas 8 et 13 comme étant « manquantes au hasard », il est plus difficile de tirer cette conclusion pour le cas 18, où deux points sont manquants. Pourquoi manquent-ils ? Le participant a-t-il mal compris la tâche ? A-t-il eu l’opportunité de répondre ? Ce sont les types de questions que vous devriez vous poser avant de remplacer les données manquantes dans SPSS. Avant d’examiner les méthodes de remplacement, gardez à l’esprit le principe suivant :
Ne remplacez jamais les données manquantes comme un processus ordinaire et habituel de l’analyse des données. Demandez-vous d’abord POURQUOI la donnée pourrait être manquante et si elle est manquante « au hasard » ou due à une erreur systématique ou à une omission dans votre expérience. Si elle est due à un schéma systématique ou à une mauvaise compréhension des instructions par le participant, c’est un scénario très différent de celui où l’observation est manquante au hasard. Si les données sont manquantes au hasard, leur remplacement est généralement plus approprié que s’il existe un schéma systématique. Soyez curieux à propos de vos données manquantes au lieu de simplement chercher à les remplacer.
Méthodes de Remplacement des Données Manquantes dans SPSS
Parcourons quelques approches pour remplacer les données manquantes. Nous démontrerons ces procédures pour notre variable `quant`. Pour accéder à cette fonctionnalité :
TRANSFORMER → REMPLACER LES VALEURS MANQUANTES
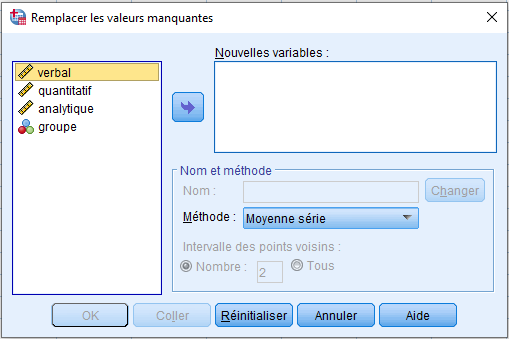
1. Remplacement par la Moyenne de la Série
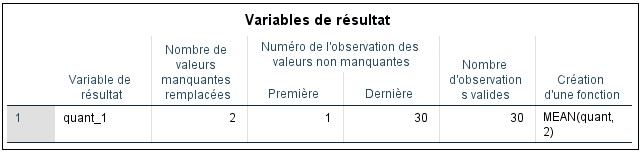
Dans ce premier exemple, nous remplacerons l’observation manquante par la moyenne de la série. Déplacez `quantitatif` vers Nouvelles variables. SPSS renommera automatiquement la variable en « quantitatif_1« , mais assurez-vous que **Series mean** est sélectionné. La moyenne de la série est définie comme la moyenne de toutes les autres observations pour cette variable. La moyenne pour `quant` est de 66,89 (vérifiez cela vous-même via Descriptives).
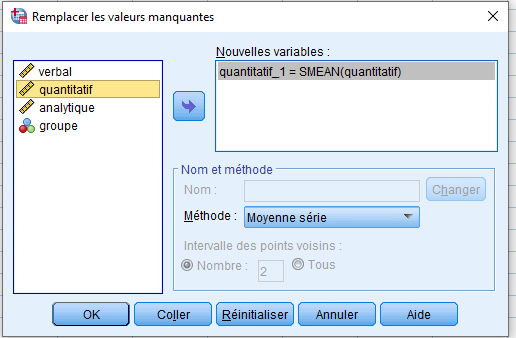
Ainsi, si SPSS remplace correctement les données manquantes, la nouvelle valeur imputée pour les cas 8 et 18 devrait être 66,89. Cliquez sur **OK** :
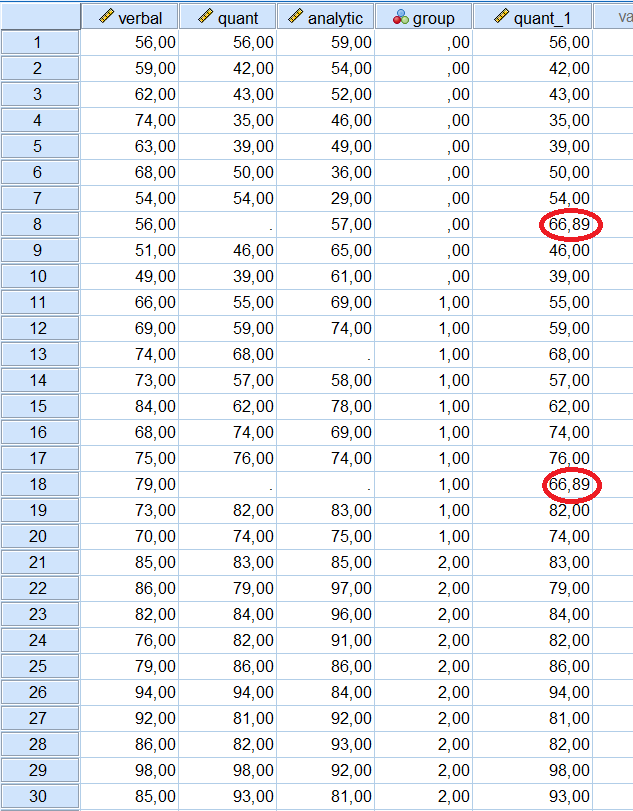
SPSS nous fournit un rapport succinct indiquant que deux valeurs manquantes ont été remplacées (pour les cas 8 et 18, sur un total de 30 cas dans notre ensemble de données). La fonction de création est la SMEAN pour quantitatif (ce qui signifie qu’il s’agit de la moyenne de la série pour la variable quantitatif). Dans la vue des données, SPSS nous montre la nouvelle variable créée avec les valeurs manquantes remplacées.
2. Remplacement par la Moyenne des Points Proches
Une autre option offerte par SPSS est de remplacer par la moyenne des points proches. Pour cette option, sous Méthode, sélectionnez Moyenne des points proches, puis cliquez sur Modifier pour l’activer dans la fenêtre Nouvelle (s) variable (s) . sous Étendue des points proches, nous utiliserons le nombre 2 (valeur par défaut). . Cela signifie que SPSS prendra les deux observations valides au-dessus du cas donné et les deux en dessous, et utilisera cette moyenne comme valeur de remplacement.
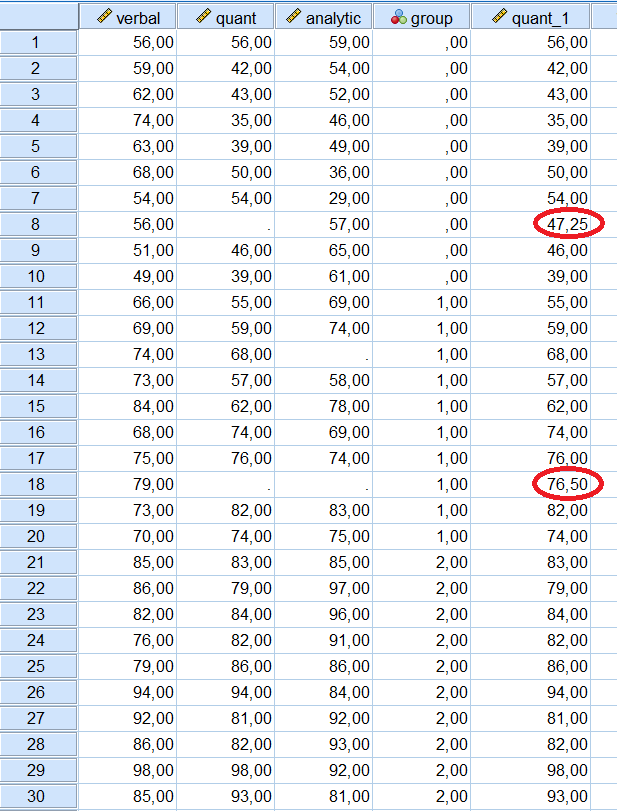
– Pour le cas 8, SPSS a pris la moyenne des deux cas au-dessus et des deux cas en dessous de l’observation manquante et l’a remplacée par cette moyenne (47,25).
– Pour le cas 18, SPSS a pris la moyenne des observations 74, 76, 82 et 74 et les a moyennées pour obtenir 76,50, qui est la valeur imputée manquante.
Autres Méthodes de Remplacement
Remplacer par la moyenne comme nous l’avons fait ci-dessus est une méthode simple, mais souvent pas la plus préférée . SPSS propose d’autres alternatives, notamment le remplacement par la médiane, l’interpolation linéaire et des méthodes plus sophistiquées telles que l’estimation du maximum de vraisemblance. SPSS propose également des applications utiles pour évaluer les schémas de données manquantes via valeurs manquantes et l’imputation multiple.
Exemple d’Analyse des Données Manquantes avec SPSS
Comme exemple de la capacité de SPSS à identifier les schémas dans les données manquantes et à remplacer ces valeurs en utilisant l’imputation, nous pouvons effectuer les étapes suivantes pour plus de détails sur cette approche) :
ANALYSE → IMPUTATION MULTIPLE → ANALYSE DE MOTIFS
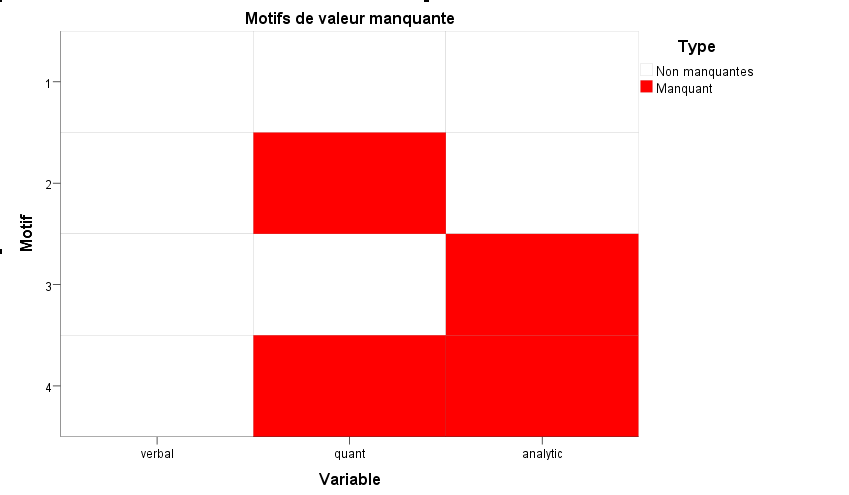
L’analyse des schémas peut vous aider à identifier s’il existe des caractéristiques systématiques dans les données manquantes ou si vous pouvez supposer qu’elles sont aléatoires. SPSS nous permet de remplacer les valeurs manquantes via :
IMPUTATION MULTIPLE → VALEURS DE DONNÉES MANQUANTES ENTRÉES
– Déplacez les variables d’intérêt vers les variables dans le modèle.
– Ajustez les Imputations à 5 (vous pouvez expérimenter avec des valeurs plus grandes, mais pour la démonstration, gardez-la à 5).
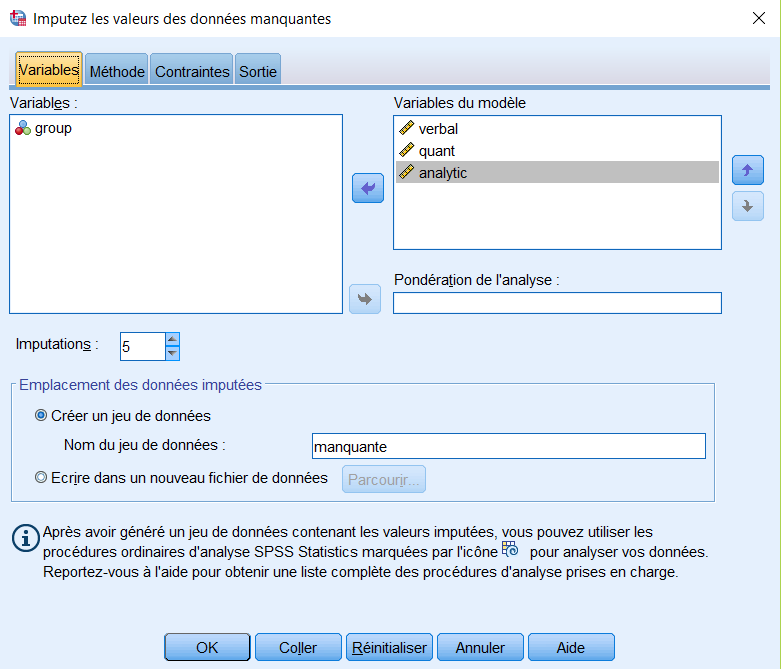
SPSS nous demande de nommer un nouveau fichier qui contiendra les données mises à jour (avec les valeurs manquantes remplacées). Sous l’onglet Méthode, nous sélectionnons spécification personnalisée et entièrement conditionnelle (MCMC) comme méthode. Nous définissons le maximum d’itérations à 10 (valeur par défaut), sélectionnons Régression linéaire comme type de modèle pour les variables d’échelle, et sous Sortie, nous cochons Modèle d’imputation et Statistiques descriptives pour les variables avec des valeurs imputées.
SPSS nous fournit un rapport sommaire sur les résultats de l’imputation, mais ce qui est plus utile est de regarder le fichier accompagnateur qui a été créé. Ce fichier contient maintenant six ensembles de données, un étant les données originales et cinq contenant les valeurs imputées. SPSS fournit également un résumé des itérations dans sa sortie :
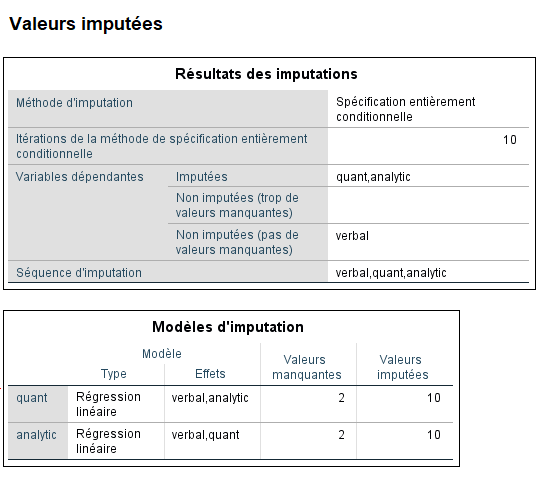
Nous voyons que la procédure a remplacé les données manquantes pour les cas 8, 13 et 18. Cependant, les imputations ci-dessus ne sont qu’une itération. Nous avons demandé à SPSS de produire cinq itérations, donc si vous parcourez le fichier, vous verrez les itérations restantes. SPSS nous fournit également un résumé des itérations dans sa sortie.
Utilisation des Données Imputées
Certaines procédures dans SPSS vous permettent d’utiliser immédiatement le fichier avec les données maintenant « complètes ». Par exemple, si nous demandons des statistiques descriptives (à partir du fichier « manquant », pas du fichier original), nous aurions ce qui suit :
VARIABLES DESCRIPTIVES = quantitatif analytique verbal
/ STATISTIQUES = MOYEN STDDEV MIN MAX.
SPSS nous donne d’abord les données originales où il y a 30 cas complets pour les observations verbal, et 28 cas complets pour les analyses et les quantitatif, , avant que l’algorithme d’imputation ne commence à remplacer les données manquantes. SPSS a ensuite créé, comme demandé, cinq nouveaux ensembles de données, imputant à chaque fois une valeur manquante pour `quantitatif` et `analytique`. Nous voyons que le N a augmenté à 30 pour chaque ensemble de données, et SPSS donne des statistiques descriptives pour chaque ensemble. Les moyennes regroupées de tous les ensembles de données pour `analytitique` et `quantitatif` sont maintenant respectivement de 71,34 et 66,69, calculées en sommant les moyennes de tous les nouveaux ensembles de données et en divisant par 5.
Exemple d’ANOVA sur les Données Imputées
Essayons une ANOVA sur le nouveau fichier :
ONEWAY quant BY group / ANALYSE MANQUANTE.
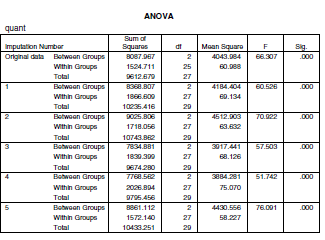
SPSS nous donne les résultats de l’ANOVA pour chaque imputation, révélant que, quelle que soit l’imputation, chaque analyse soutient le rejet de l’hypothèse nulle. Nous avons des preuves qu’il existe des différences de moyennes entre les groupes sur `quantitatif`.
Conclusion de l’ANOVA
Une analyse de variance unidirectionnelle (ANOVA) a été réalisée pour comparer les performances quantitatives des étudiants, mesurées sur une échelle continue, en fonction de leur niveau d’étude (aucun, un peu, ou beaucoup). La taille totale de l’échantillon était de 30, avec chaque groupe ayant 10 observations. Deux cas (8 et 18) avaient des valeurs manquantes sur `quantitatif`. La spécification conditionnelle complète de SPSS a été utilisée pour imputer les valeurs pour cette variable, avec cinq imputations demandées. Chaque imputation a donné des ANOVA qui rejettent l’hypothèse nulle d’égalité des moyennes de population (p < 0,001). Par conséquent, il existe des preuves suggérant que la performance quantitative est fonction du temps que l’étudiant a passé à étudier pour l’évaluation.
Conclusion
Nous terminons cette section en réitérant l’avertissement – soyez très prudents lorsque vous remplacez des données manquantes. Statistiquement, cela peut sembler une bonne chose à faire pour obtenir un ensemble de données plus complet, mais scientifiquement, cela signifie que vous devinez (bien que de manière sophistiquée) les valeurs manquantes. Si vous ne remplacez pas les données manquantes, les méthodes courantes pour gérer les cas avec des données manquantes incluent la suppression par liste et la suppression par paire. La suppression par liste exclut les cas avec des données manquantes sur n’importe quelle variable de la liste, tandis que la suppression par paire exclut les cas uniquement pour les variables sur lesquelles l’analyse est effectuée. Pour la plupart des procédures de ce livre, en particulier les multivariées, la suppression par liste est généralement préférée à la suppression par paire.