Rappelons la nature du modèle que nous souhaitons exécuter. Nous pouvons spécifier l’équation de régression comme suit :
GAF=AGE+PRETHERAPY+N_THERAPY
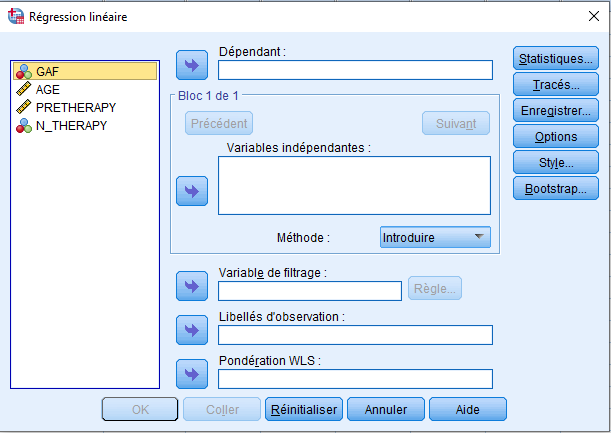
Pour exécuter la régression :
ANALYSE→REˊGRESSION→LINEˊAIRE.
-
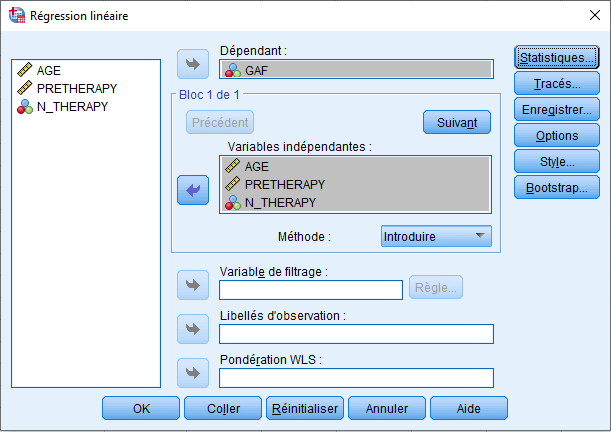
Nous déplaçons GAF vers la boîte Dépendante (puisque c’est notre variable dépendante ou « réponse »).
-
Nous déplaçons AGE, PRETHERAPY et N_THERAPY vers les variables Indépendante(s) (puisque ce sont nos prédicteurs, les variables que nous souhaitons voir prédire simultanément GAF).
-
Sous la variable Indépendante(s), la Méthode est notée et est actuellement, par défaut, définie sur Introduirr. Cela signifie que SPSS effectuera la régression sur tous les prédicteurs simultanément plutôt que de manière séquentielle (la sélection progressive, la sélection arrière et la sélection pas à pas sont d’autres options pour l’analyse de régression, comme nous le verrons bientôt).
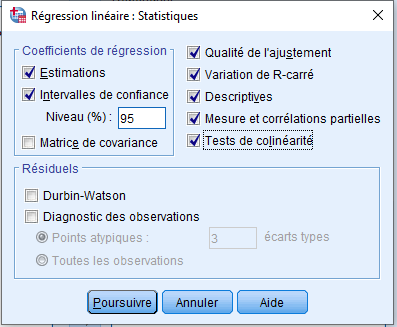
Ensuite, nous cliquerons sur la boîte Statistiques et sélectionnerons quelques options :
-
Sous Coefficients de régression, nous avons sélectionné Estimations et Intervalles de confiance (à un niveau de 95 %). Nous avons également sélectionné Qualité de l’ajustement, Variation du R-carré, Descriptives, Mesure et Corrélations partielles et Tests de colinéarité. Sous Résiduels, nous avons sélectionés Diagnostic des observations par Points atypiques et en dehors de 3 écarts types.
-
Cliquez sur Poursuivre. Nous aurions sélectionné le test de Durbin-Watson si nous avions eu des données chronologiques et souhaitions savoir s’il existait des preuves que les erreurs étaient corrélées.
-
Il y a d’autres options que nous pouvons sélectionner sous Graphiques et Enregistrer dans la fenêtre principale de Régression linéaire, mais comme la plupart de ces informations concernent l’évaluation des résidus, nous reportons cette étape à plus tard, après avoir ajusté le modèle. Pour l’instant, nous voulons obtenir les résultats de notre régression et démontrer l’interprétation des estimations des paramètres.
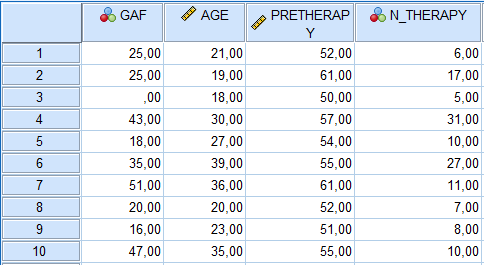
Lorsque nous exécutons la régression multiple, nous obtenons ce qui suit (ci-dessous la syntaxe qui représente les sélections que nous avons faites via l’interface graphique) :

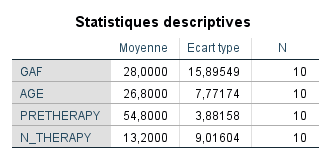
À gauche se trouvent certaines des statistiques descriptives que nous avions demandées pour notre régression. Ce sont les mêmes informations que nous aurions obtenues dans notre exploration préliminaire des données. Il est cependant utile de vérifier que N=10 pour chaque variable, sinon cela indiquerait que nous avons des valeurs manquantes ou des données incomplètes. Dans nos résultats, nous voyons que GAF a une moyenne de 28,0, AGE a une moyenne de 26,8, PRETHERAPY a une moyenne de 54,8 et N_THERAPY a une moyenne de 13,2. Les écarts types sont également fournis.
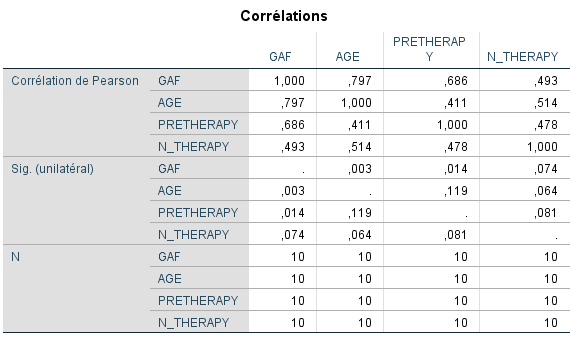
SPSS nous fournit également une matrice de coefficients de corrélation de Pearson entre toutes les variables, ainsi que des valeurs p (Sig. unilatéral) indiquant si elles sont statistiquement significatives. Ayant déjà examiné les relations bivariées générales entre les variables lorsque nous avons tracé les diagrammes de dispersion, cette matrice nous fournit des preuves supplémentaires que les variables sont au moins quelque peu linéairement liées dans l’échantillon. Nous ne nous intéressons pas à la signification statistique des corrélations pour effectuer la régression multiple, et puisque la taille de l’échantillon est assez petite (N=10), il n’est guère surprenant que beaucoup de corrélations ne soient pas statistiquement significatives.

Ensuite, SPSS indique quelles variables ont été entrées dans la régression et lesquelles ont été exclues. Comme nous avons effectué une régression « entrée complète » (rappelons que nous avions sélectionné Entrer sous Méthode), toutes nos variables seront entrées dans la régression simultanément, et aucune ne sera supprimée. Lorsque nous effectuerons des régressions progressives et pas à pas, par exemple, cette boîte Variables supprimées sera un peu plus occupée !

Ci-dessus se trouve le Résumé du modèle pour la régression. Pour un compte rendu relativement détaillé de ce que signifient toutes ces statistiques et de la théorie qui les sous-tend, consultez Denis (2016, chapitres 8 et 9) ou tout livre sur la régression. Nous interprétons chaque statistique ci-dessous :
• R de 0,890 représente le coefficient de corrélation multiple entre la variable réponse (GAF) et les trois prédicteurs considérés simultanément (AGE, PRETHERAPY, N_THERAPY). C’est-à-dire que c’est la corrélation entre GAF et une combinaison linéaire de AGE + PRETHERAPY et N_THERAPY. Le R multiple peut varier en valeur de 0 à 1,0 (notez qu’il ne peut pas être négatif, contrairement au r de Pearson ordinaire sur deux variables qui varie de −1,0 à +1,0).
-
R-carré est le carré du coefficient de corrélation multiple (appelé coefficient de détermination multiple) et représente la proportion de variance dans la variable réponse expliquée par la connaissance simultanée des prédicteurs. C’est-à-dire que c’est la proportion de variance expliquée par le modèle, le modèle étant la régression de GAF sur la combinaison linéaire de AGE + PRETHERAPY et N_THERAPY.
-
R-carré ajusté est une version alternative du R-carré et est plus petit que le R-carré (rappelons que nous avions discuté du R-carré ajusté plus tôt dans le contexte de la régression linéaire simple). Le R-carré ajusté prend en compte le nombre de paramètres ajustés au modèle par rapport à leur contribution à l’ajustement du modèle.
-
Erreur standard de l’estimation est l’écart type des résidus pour le modèle (avec des degrés de liberté différents de l’écart type typique). Une valeur très faible ici indiquerait que le modèle s’ajuste assez bien, et une valeur très élevée suggérerait que le modèle ne fournit pas un très bon ajustement aux données. Lorsque nous interpréterons le tableau ANOVA pour la régression sous peu, nous discuterons de son carré, qui est la Variance de l’estimation.
-
Ensuite, SPSS rapporte les « Statistiques de changement ». Celles-ci sont plus applicables lorsque nous effectuons des régressions hiérarchiques, progressives ou pas à pas. Lorsque nous ajoutons des prédicteurs à un modèle, nous nous attendons à ce que le R-carré augmente. Ces statistiques de changement nous indiquent si l’incrément du R-carré est statistiquement significatif, ce qui signifie grossièrement que c’est plus qu’un changement que nous attendrions par hasard. Pour nos données, puisque nous avons entré tous les prédicteurs simultanément dans le modèle, le Changement du R-carré est équivalent à la statistique R-carré originale. Le F de changement de 7,582 est la statistique F associée au modèle, sur les degrés de liberté donnés de 3 et 6, ainsi que la valeur p de 0,018. Notez que ces informations dupliquent les informations trouvées dans le tableau ANOVA qui sera discuté sous peu. Encore une fois, la raison en est que nous avons effectué une régression à entrée complète. Gardez un œil sur vos Statistiques de changement lorsque vous n’entrez pas vos prédicteurs simultanément pour avoir une idée de la variance supplémentaire expliquée par chaque prédicteur entré dans le modèle.
Ensuite, SPSS rapporte le tableau récapitulatif ANOVA pour notre analyse :
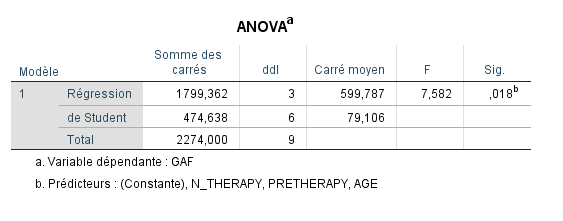
Le tableau ANOVA pour la régression révèle comment la variance dans la régression a été partitionnée, de manière analogue à ce que fait le tableau ANOVA dans la procédure Analyse de variance. Bref, voici ce que ces nombres indiquent :
-
SS Total de 2274,000 est partitionné en SS Régression (1799,362) et SS Résiduel (474,638). C’est-à-dire, 1799,362 + 474,638 = 2274,000.
-
Qu’est-ce qui rend notre modèle réussi pour expliquer la variance dans GAF ? Ce qui le rendrait réussi, c’est si SS Régression était grand par rapport à SS Résiduel. SS Régression mesure la variabilité due à l’imposition de l’équation de régression linéaire sur les données. SS Résiduel nous donne une mesure de toute la variabilité non expliquée par le modèle. Naturellement, notre espoir est que SS Régression soit grand par rapport à SS Résiduel. Pour nos données, c’est le cas.
-
Pour obtenir une mesure de combien SS Régression est grand par rapport à la variation totale dans les données, nous pouvons prendre le ratio SS Régression/SS Total, ce qui donne 1799,362/2274,000 = 0,7913. Notez que cette valeur de 0,7913 est, en réalité, la valeur du R-carré que nous avons trouvée dans notre tableau Résumé du modèle. Cela signifie qu’environ 79 % de la variance dans GAF est expliquée par nos trois prédicteurs simultanément.
-
Les degrés de liberté pour la Régression, égaux à 3, sont égaux au nombre de prédicteurs dans le modèle (3).
-
Les degrés de liberté pour le Résiduel sont égaux à n−k−1, où « n » est la taille de l’échantillon. Pour nos données, nous avons 10−3−1=6.
-
Les degrés de liberté pour le Total sont égaux à la somme des degrés de liberté ci-dessus (c’est-à-dire 3+6=9). C’est aussi égal au nombre de cas dans les données moins 1 (c’est-à-dire 10−1=9).
-
Le Carré moyen pour la Régression, égal à 599,787, est calculé comme SS Régression/dl = 1799,362/3 = 599,787.
-
Le Carré moyen pour le Résiduel, égal à 79,106, est calculé comme SS Résiduel/dl = 474,638/6 = 79,106. Le nombre 79,106 est appelé la variance de l’estimation et est le carré de l’erreur standard de l’estimation que nous avons considérée plus tôt dans les résultats du Résumé du modèle. Rappelons que ce nombre était 8,89418. La racine carrée de 79,106 est égale à ce nombre.
-
La statistique F, égale à 7,582, est calculée par le ratio MS Régression sur MS Résiduel. Pour nos données, le calcul est 599,787/79,106 = 7,582.
-
La valeur p de 0,018 indique si le F obtenu est statistiquement significatif. Les niveaux de signification conventionnels sont généralement fixés à 0,05 ou moins. Ce que le nombre 0,018 signifie littéralement, c’est que la probabilité d’obtenir une statistique F comme celle que nous avons obtenue (c’est-à-dire 7,582) ou plus extrême est égale à 0,018. Comme cette valeur est inférieure à un niveau prédéfini de 0,05, nous considérons que F est statistiquement significatif et rejetons l’hypothèse nulle que le multiple dans la population à partir de laquelle ces données ont été tirées est égal à zéro. C’est-à-dire que nous avons des preuves suggérant que le R multiple dans la population est différent de zéro.
Ensuite, SPSS rapporte les coefficients pour le modèle, ainsi que d’autres informations que nous avons demandées telles que les intervalles de confiance, les corrélations d’ordre zéro, partielles et semi-partielles, et les statistiques de colinéarité :

Nous interprétons les nombres ci-dessus :
-
SPSS indique qu’il s’agit du Modèle 1, qui consiste en une constante, AGE, PRETHERAPY et N_THERAPY. Le fait que ce soit le « Modèle 1 » n’est pas important, puisque c’est le seul modèle que nous exécutons. Si nous avions effectué une régression hiérarchique où nous comparions des modèles alternatifs, alors nous pourrions avoir 2 ou 3 modèles ou plus, et donc l’identification du « Modèle 1 » serait plus pertinente et importante.
-
La Constante dans le modèle est l’ordonnée à l’origine du modèle. C’est la valeur prédite pour la variable réponse GAF pour des valeurs de AGE, PRETHERAPY et N_THERAPY toutes égales à 0. C’est-à-dire qu’elle répond à la question, Quelle est la valeur prédite pour quelqu’un d’âge zéro, zéro sur PRETHERAPY et zéro sur N_THERAPY ? Bien sûr, la question n’a pas beaucoup de sens, puisque personne ne peut avoir un âge de zéro ! Pour cette raison, les prédicteurs dans un modèle sont parfois centrés sur la moyenne si l’on souhaite interpréter l’ordonnée à l’origine de manière significative. Le centrage sur la moyenne soustrairait la moyenne de chaque variable du score donné, et donc une valeur de AGE = 0 ne correspondrait plus à un véritable zéro sur l’âge, mais indiquerait plutôt l’ÂGE MOYEN. Les régressions avec centrage sur la moyenne dépassent le cadre de notre chapitre actuel, cependant, nous laissons donc ce sujet pour l’instant. Pour plus de détails, voir Draper et Smith (1995). Tel quel, le coefficient de −106,167 représente la valeur prédite pour GAF lorsque AGE, PRETHERAPY et N_THERAPY sont tous égaux à 0.
-
Le coefficient pour AGE, égal à 1,305, est interprété comme suit : pour une augmentation d’une unité dans AGE, en moyenne, nous nous attendons à ce que GAF augmente de 1,305 unités, compte tenu de l’inclusion de tous les autres prédicteurs dans le modèle.
-
Le coefficient pour PRETHERAPY, égal à 1,831, est interprété comme suit : pour une augmentation d’une unité dans PRETHERAPY, en moyenne, nous nous attendons à ce que GAF augmente de 1,831 unités, compte tenu de l’inclusion de tous les autres prédicteurs dans le modèle.
-
Le coefficient pour N_THERAPY, égal à −0,086, est interprété comme suit : pour une augmentation d’une unité dans N_THERAPY, en moyenne, nous nous attendons à ce que GAF diminue de 0,086 unités, compte tenu de l’inclusion de tous les autres prédicteurs dans le modèle. Il signifie une diminution parce que le coefficient est négatif.
-
Les erreurs standard estimées dans la colonne suivante sont utilisées pour calculer un test t pour chaque coefficient, et finalement nous aider à décider si nous rejetons ou non l’hypothèse nulle que le coefficient de régression partielle est égal à 0. Lorsque nous divisons la Constante de −106,167 par l’erreur standard de 45,578, nous obtenons la statistique t résultante de −2,329 (c’est-à-dire −106,167/45,578=−2,329). La probabilité d’un tel t ou plus extrême est égale à 0,059 (Sig. pour la Constante). Comme elle n’est pas inférieure à 0,05, nous décidons de ne pas rejeter l’hypothèse nulle. Ce que cela signifie pour ces données, c’est que nous n’avons pas suffisamment de preuves pour douter que la Constante dans le modèle est égale à une valeur d’hypothèse nulle de 0.
-
L’erreur standard pour AGE est égale à 0,456. Lorsque nous divisons le coefficient pour AGE de 1,305 par 0,456, nous obtenons la statistique t de 2,863, qui est statistiquement significative (p=0,029). C’est-à-dire que nous avons des preuves suggérant que le coefficient de régression partielle dans la population pour AGE est différent de 0.
-
Les erreurs standard pour PRETHERAPY et N_THERAPY sont utilisées de manière analogue. Ni PRETHERAPY ni N_THERAPY ne sont statistiquement significatives à p<0,05. Pour plus de détails sur ce que ces erreurs standard signifient théoriquement
-
Les Coefficients standardisés (Bêta) sont des coefficients de régression partielle qui ont été calculés sur des scores z plutôt que sur des scores bruts. En tant que tels, leur unité est celle de l’écart type. Nous interprétons le coefficient pour AGE de 0,638 comme suit : pour une augmentation d’un écart type dans AGE, en moyenne, nous nous attendons à ce que GAF augmente de 0,638 écart type. Nous interprétons les deux autres Bêtas (pour PRETHERAPY et N_THERAPY) de manière analogue.
-
Ensuite, nous voyons l’Intervalle de confiance à 95 % pour B avec des bornes inférieures et supérieures. Nous ne nous intéressons généralement pas à l’intervalle de confiance pour l’ordonnée à l’origine, nous passons donc directement à l’interprétation de l’intervalle de confiance pour AGE. La borne inférieure est 0,190 et la borne supérieure est 2,421. Nous sommes sûrs à 95 % que la borne inférieure de 0,190 et la borne supérieure de 2,421 couvriront (ou « captureront ») le véritable coefficient de régression dans la population. Nous interprétons les intervalles de confiance pour PRETHERAPY et N_THERAPY de manière analogue.
-
Ensuite viennent les corrélations d’ordre zéro, partielles et semi-partielles. Les corrélations d’ordre zéro sont des corrélations bivariées ordinaires entre le prédicteur donné et la variable réponse, sans tenir compte des autres variables dans le modèle. Les corrélations partielles et semi-partielles dépassent le cadre de ce livre. Informellement, ces corrélations sont celles entre le prédicteur donné et la réponse, mais elles éliminent la variabilité due aux autres prédicteurs dans le modèle. Nous reviendrons sur la corrélation semi-partielle (au moins conceptuellement) lorsque nous discuterons de la régression pas à pas.
-
Enfin, SPSS nous fournit (comme nous l’avions demandé) les Statistiques de colinéarité. Le VIF est un indicateur qui vous dit à quel point la variance d’une estimation de paramètre est « gonflée » (c’est pourquoi on l’appelle le Facteur d’Inflation de la Variance). La variance pour une estimation de paramètre donnée peut être gonflée en raison de la colinéarité avec d’autres variables dans le modèle (autres qu’avec la variable réponse, où nous nous attendons à des corrélations plutôt élevées). Si le VIF est supérieur à 5 environ, il peut être bon de vérifier qu’aucune de vos variables ne mesure la « même chose ». Même des VIF élevés ne signifient pas que vous devez changer quoi que ce soit dans votre modèle, mais certainement si les VIF approchent 10, cela peut indiquer un problème potentiel de colinéarité. La Tolérance est l’inverse du VIF et est calculée comme 1/VIF. Alors que des valeurs élevées de VIF sont « mauvaises », des valeurs élevées de tolérance sont « bonnes ». La Tolérance varie de 0 à 1, tandis que le VIF varie théoriquement de 1 et plus. Nos VIF pour notre analyse sont assez faibles, indiquant que nous n’avons pas de problèmes de multicollinéarité.