Dans la régression multiple abordée jusqu’à présent, nous avons procédé en incluant simultanément tous les prédicteurs dans la régression. Par exemple, pour prédire GAF, nous avons inclus AGE, PRETHERAPY et N_THERAPY en même temps dans notre régression et observé les effets de chaque variable en présence des autres. Cette approche dans SPSS est appelée l’approche d’entrée complète, et elle est activée en sélectionnant « Enter » comme méthode lors de l’exécution de la régression :
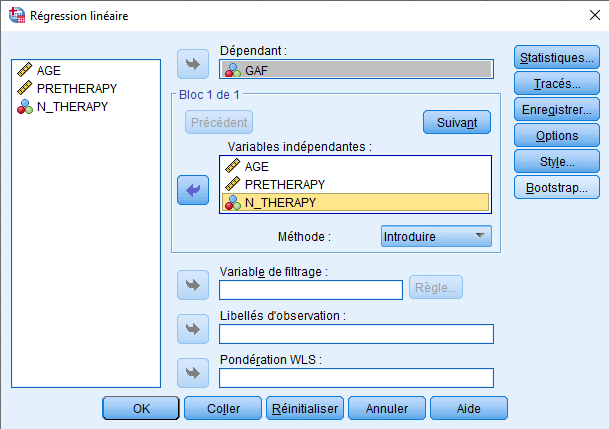
Lorsque nous souhaitons inclure tous les prédicteurs simultanément dans la régression, nous nous assurons que « EIntroduire » est sélectionné sous « Methode ».
Cependant, il arrive que les chercheurs souhaitent utiliser une approche différente de la régression par entrée complète, comme l’ajout ou la suppression de variables une par une après avoir observé l’impact des variables déjà incluses dans le modèle.
Dans la régression hiérarchique, le chercheur décide de l’ordre exact dans lequel les variables sont introduites dans le modèle. Par exemple, un chercheur pourrait hypothétiser que AGE est un prédicteur influent et choisir de l’inclure en premier dans le modèle. Ensuite, avec cette variable déjà incluse, il pourrait observer l’effet de PRETHERAPY en plus de celui de AGE (ou en d’autres termes, en maintenant AGE constant). Voici comment procéder :
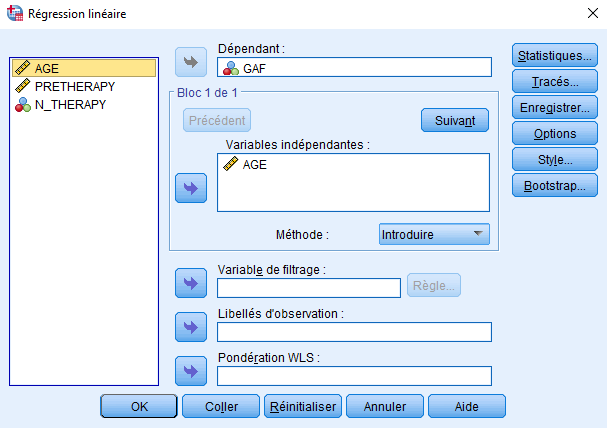
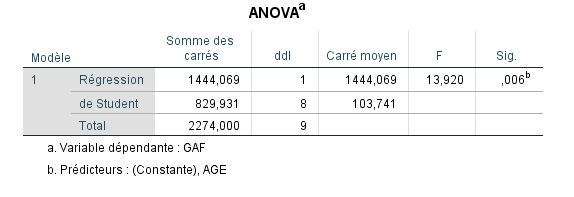
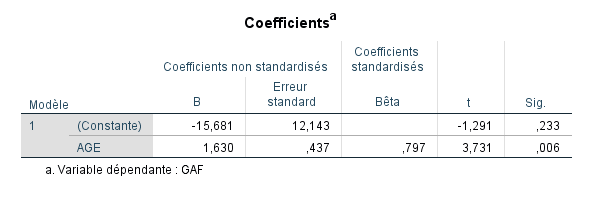
L’effet de AGE seul dans le modèle est statistiquement significatif (p=0.006).


Ensuite, le chercheur ajoute le deuxième prédicteur. Il sélectionne « Suivant » pour construire le deuxième modèle et inclut à la fois AGE et PRETHERAPY (notez que l’interface affiche maintenant « Block 2 of 2 »). Voici un extrait partiel des résultats :
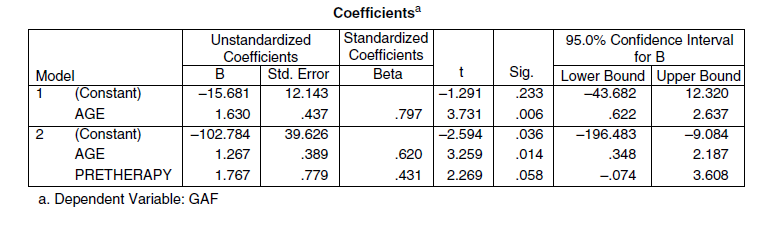
Avec PRETHERAPY inclus dans le modèle, le chercheur peut observer si cette variable est statistiquement significative compte tenu de la présence de AGE, et évaluer directement la contribution de PRETHERAPY. La valeur p de 0.058 pour PRETHERAPY reflète son importance après l’inclusion de AGE. Il ne s’agit pas de la valeur p pour PRETHERAPY seule. Notons également que nous construisons simplement différents modèles de régression. Le modèle 1 ou le modèle 2 pourraient être considérés comme des modèles « d’entrée complète » s’ils étaient exécutés séparément. Cependant, l’objectif de la régression hiérarchique est de permettre au chercheur de choisir l’ordre d’inclusion des variables en fonction de sa théorie substantielle.
Vous pourriez penser à ce stade : « Cela ressemble beaucoup à l’exemple de médiation que nous étudierons plus tard dans ce chapitre », et vous auriez raison. L’analyse de médiation utilise essentiellement cette approche hiérarchique pour établir ses preuves. L’analyse de médiation n’est pas « équivalente » à la régression hiérarchique, mais elle emploie une approche hiérarchique pour vérifier si le chemin original (dans nos données, ce chemin sera AGE prédictif de GAF) diminue ou disparaît après l’inclusion de l’hypothétique médiateur (PRETHERAPY). Nous aborderons la médiation sous peu.
Résumé des résultats :
Une régression linéaire hiérarchique a été réalisée pour prédire GAF. Le premier prédicteur inclus dans le modèle était l’âge, expliquant environ 63.5% de la variance de GAF (p=0.006). À la deuxième étape, PRETHERAPY a été inclus (p=0.058), augmentant la variance expliquée par le modèle complet à 79.0%.