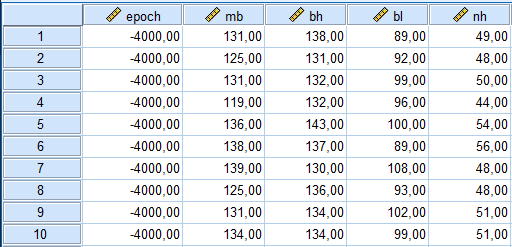
Que nous a révélé notre MANOVA ? Notre MANOVA nous a essentiellement indiqué que sur la combinaison linéaire de mb + bh + bl + nh, nous avons des preuves suggérant des différences de moyennes dans la population. Mais rappelons ce qu’est une combinaison linéaire dans le contexte de la MANOVA. Il ne s’agit pas simplement de sommer mb à nh. Une combinaison linéaire est une pondération de ces variables. La MANOVA nous a montré qu’il y avait des différences de moyennes sur une combinaison linéaire optimisée de mb + bh + bl + nh, mais elle ne nous a pas révélé à quoi ressemblait cette pondération. C’est là qu’intervient l’analyse discriminante. L’analyse discriminante va nous dévoiler la ou les combinaisons linéaires optimisées qui ont généré les différences de moyennes dans notre MANOVA. Si nous appelons « w » les poids de notre combinaison linéaire, alors nous avons :
Combinaison linéaire = w1(mb) + w2(bh) + w3(bl) + w4(nh)
L’analyse discriminante va nous indiquer quelles sont réellement les valeurs des poids w1, w2, w3 et w4, afin que nous puissions mieux comprendre la nature de cette ou ces fonctions qui discriminent si bien entre les groupes d’époques (et génèrent équivalemment des différences de moyennes). Nous soulignerons les similitudes entre MANOVA et DISCRIM au fur et à mesure.
Pour réaliser une analyse discriminante dans SPSS : ANALYSER → CLASSiFIER → ANALYSE DISCRIMINANTE
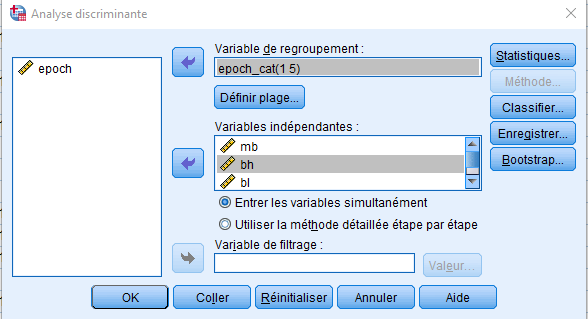
Nous déplaçons epoch_cat dans la boîte Grouping Variable et mb, bh, bl et nh dans la boîte des indépendantes. SPSS nous demandera de définir la plage de la variable de regroupement. Le minimum est ~4000 et le maximum est 150, mais SPSS n’acceptera pas un nombre minimum aussi bas. Une solution simple est de recoder la variable en nombres de 1 à 5 (ci-dessous). Nous appelons notre variable recodée epoch_cat, ayant maintenant des niveaux de 1 à 5.
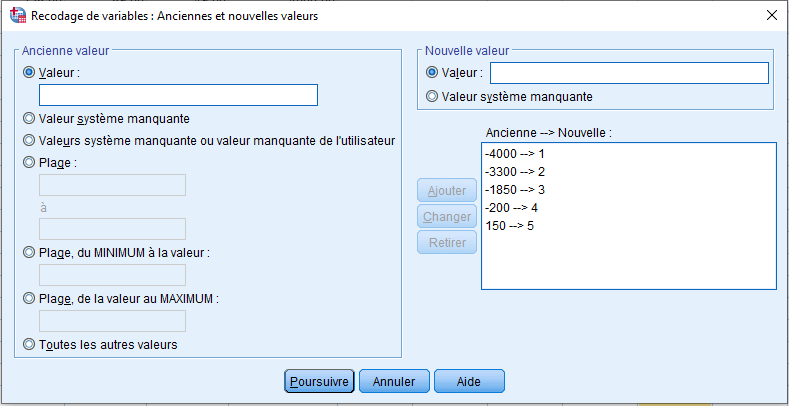
Enfin, avant d’exécuter la procédure, nous nous assurons également que Entrer les variables simultanément est sélectionné.
Résumé des Fonctions Discriminantes Canoniques
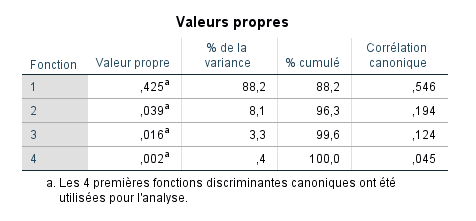
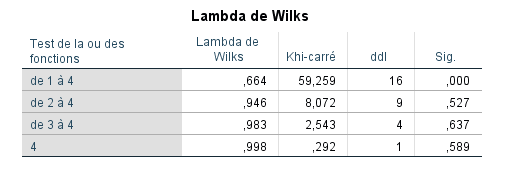
Quatre fonctions discriminantes ont été extraites de la procédure d’analyse discriminante. La première fonction a donné une valeur propre de 0,425 et, parmi les quatre fonctions, elle a représenté 88,2 % des valeurs propres extraites* (voir l’interprétation ci-dessous, points 2 à 5). La première fonction était très importante, donnant une corrélation canonique au carré de 29,81 % (c’est-à-dire 0,546 × 0,546), tandis que les fonctions restantes étaient beaucoup moins pertinentes. Seule la première fonction était statistiquement significative (Wilks = 0,664, p = 0,000).
Ci-dessus, SPSS rapporte des résultats utiles pour interpréter l’analyse discriminante :
-
SPSS a produit quatre fonctions discriminantes. Ces fonctions sont numérotées de 1 à 4 dans la première colonne du Résumé des Fonctions Discriminantes Canoniques. (Le Lambda de Wilks dans le tableau accompagnant indique que seule la fonction 1 est statistiquement significative.)
-
La deuxième colonne contient les valeurs propres. Les valeurs propres ont des interprétations légèrement différentes selon qu’elles sont obtenues dans une analyse discriminante ou une analyse en composantes principales (par exemple, la valeur propre n’est pas une variance dans l’analyse discriminante, bien qu’elle le soit dans l’analyse en composantes principales (Rencher et Christensen 2012)). Pour DISCRIM, la valeur propre nous fournit une mesure de « l’importance » de la fonction discriminante, où des valeurs propres plus grandes indiquent une plus grande importance que des valeurs plus petites. Nous pouvons voir que la fonction 1 est la plus importante en termes de capacité discriminante, car elle est plus grande que les valeurs propres des fonctions 2 à 4.
-
En utilisant les valeurs propres, nous pouvons calculer les nombres dans la colonne 3, % de Variance, en prenant la valeur propre respective et en la divisant par la somme des valeurs propres. Pour la première fonction, la « proportion de variance » expliquée est 0,425/(0,425 + 0,039 + 0,016 + 0,002) = 0,882. C’est-à-dire que la première fonction discriminante représente 88,2 % de la variance de celles extraites. Il convient de noter que l’utilisation des valeurs propres de manière « proportion de variance expliquée » est, à strictement parler, quelque peu inexacte, car comme mentionné, les valeurs propres dans l’analyse discriminante ne sont pas de véritables « variances » (elles le sont dans l’analyse en composantes principales, mais pas dans l’analyse discriminante). Cependant, pragmatiquement, le langage « proportion de variance » est souvent utilisé lors de l’interprétation des fonctions discriminantes (même SPSS le fait en intitulant la colonne 3 par « % de Variance »). Voir Rencher et Christensen (2012) pour une explication plus approfondie des subtilités sur ce point. La règle générale est que lors de la division des valeurs propres par la somme des valeurs propres dans l’analyse discriminante, il est préférable de simplement se référer à ce ratio comme une mesure d’importance plutôt que de variance. Des ratios plus élevés indiquent une plus grande importance pour la fonction donnée que des ratios plus faibles.
-
La deuxième fonction représente 8,1 % de la variance (0,039/0,482 = 0,08). La 3ème fonction représente 3,3 %, tandis que la dernière fonction représente 0,4 %. La colonne 4 nous fournit le pourcentage cumulé de variance expliquée.
-
Il est important de noter que les nombres dans les colonnes 3 et 4 ne sont pas des tailles d’effet pour la fonction discriminante. Ils révèlent simplement comment les valeurs propres se répartissent entre les fonctions discriminantes. Pour une mesure de la taille de l’effet pour chaque fonction discriminante, nous devons nous tourner vers la cinquième colonne ci-dessus, qui est celle de la Corrélation Canonique pour chaque fonction discriminante.
-
La corrélation canonique au carré nous fournit une mesure de la taille de l’effet (ou « association ») pour la fonction discriminante donnée. Pour la première fonction, lorsque nous élevons au carré la corrélation canonique, nous obtenons (0,546)(0,546)=0,2981. C’est-à-dire que la taille de l’effet pour la première fonction discriminante est égale à 0,2981. Nous aurions également pu obtenir le nombre de 0,2981 par le ratio de la valeur propre à (1 + valeur propre). C’est-à-dire que la première fonction représente près de 30 % de la variance. La corrélation canonique au carré est une mesure de type R-carré similaire à celle de la régression multiple. C’est-à-dire qu’il s’agit de la corrélation au carré maximale entre la fonction discriminante donnée et la meilleure combinaison linéaire des variables d’appartenance au groupe (voir Rencher et Christensen (2012) pour plus de détails sur cette interprétation).
-
La proportion de variance expliquée par la deuxième fonction discriminante est égale à (0,194)(0,194)=0,038, etc., pour les fonctions discriminantes restantes. Nous pouvons voir alors que la première fonction discriminante semble « faire tout le travail » en ce qui concerne la discrimination entre les niveaux de la variable de regroupement.
-
Encore une fois, il est important de noter et de souligner que la colonne % de Variance concerne les valeurs propres et non les corrélations canoniques. Diviser la valeur propre par la somme totale des valeurs propres donne une mesure de l’importance de la fonction, mais elle ne fournit pas une mesure d’association ou de taille d’effet. Pour cela, il faut élever au carré la corrélation canonique. Notez que 88,2 % pour la première fonction discriminante ne correspond pas à la corrélation canonique au carré de (0,546)(0,546)=0,2981.
-
Au fur et à mesure que nous passons de la fonction 1 à la fonction 4, chaque fonction représente une proportion de variance plus petite en termes de valeurs propres et en termes de corrélation canonique au carré.
-
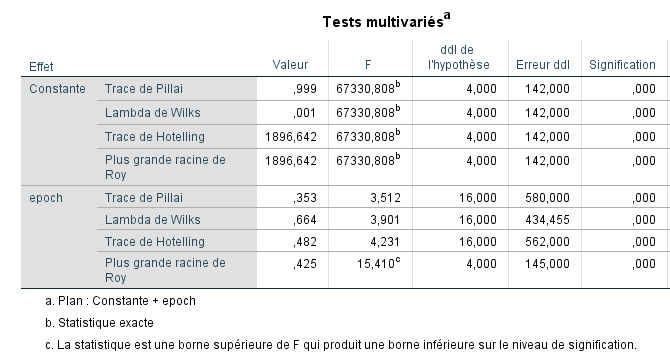
Nous pouvons calculer les statistiques multivariées de la MANOVA directement à partir du tableau ci-dessus en référence aux valeurs propres. Rappelons quels étaient les tests multivariés pour ces données :
-
Pillai’s Trace = Somme des corrélations canoniques au carré : (0,546)² + (0,194)² + (0,124)² + (0,045)² = 0,353
-
Wilks’ Lambda = Somme des produits 1/(1+valeur propre) : (0,70175)(0,96246)(0,98425)(0,9980) = 0,663
-
Hotelling’s Trace = Somme des valeurs propres : 0,425 + 0,039 + 0,016 + 0,002 = 0,482
-
Roy’s Largest Root : Plus grande valeur propre extraite : 0,425 (notez que SPSS définit cette statistique comme la plus grande valeur propre plutôt que (plus grande valeur propre)/(1 + plus grande valeur propre) comme défini précédemment dans ce chapitre et dans Rencher et Christensen (2012)).
Dans notre interprétation des résultats de MANOVA et DISCRIM, à plusieurs endroits nous sommes tombés sur quelque chose connu sous le nom de corrélation canonique et l’avons même utilisé comme mesure de la taille de l’effet. Mais qu’est-ce exactement que la corrélation canonique ? Bien que dans ce livre nous n’en discutions pas en détail et ne la mentionnions qu’en passant comme elle se rapporte aux résultats de la MANOVA et de l’analyse discriminante, la corrélation canonique est en fait sa propre méthode statistique dans laquelle on souhaite corréler des combinaisons linéaires de variables. Prenant un exemple de l’innovateur de la corrélation canonique, Harold Hotelling, imaginons que nous étions intéressés à corréler quelque chose appelé capacité de lecture à quelque chose appelé capacité arithmétique. Cependant, la capacité de lecture est composée de deux choses – (i) la vitesse de lecture et (ii) la puissance de lecture – et la capacité arithmétique est également composée de deux choses : (i) la vitesse arithmétique et (ii) la puissance arithmétique. Donc en réalité, ce que nous voulons réellement corréler est ce qui suit :
VITESSE DE LECTURE + PUISSANCE DE LECTURE AVEC VITESSE ARITHMÉTIQUE + PUISSANCE ARITHMÉTIQUE
Lorsque nous attribuons des poids à la vitesse de lecture et à la puissance de lecture, puis à la vitesse arithmétique et à la puissance arithmétique, nous aurons défini des combinaisons linéaires de variables, et lorsque nous corrélons ces deux combinaisons linéaires, nous aurons obtenu la corrélation canonique. La corrélation canonique est définie comme la corrélation bivariée maximale entre deux combinaisons linéaires de variables. Mais pourquoi la corrélation canonique apparaît-elle dans une discussion sur la MANOVA et l’analyse discriminante ? Elle le fait parce que les corrélations canoniques sont en fait au cœur de nombreuses techniques multivariées, car dans nombre de ces méthodes, à un niveau technique, nous corrélons d’une certaine manière des combinaisons linéaires. Dans le cas de la MANOVA, par exemple, nous corrélons un ensemble de variables dépendantes avec un ensemble de variables indépendantes, même si la question de recherche n’est pas posée de cette façon. Sous-jacent à notre MANOVA se trouve la corrélation entre des ensembles de variables, qui est la corrélation canonique. Les corrélations canoniques apparaissent également dans d’autres endroits, mais rarement aujourd’hui les chercheurs effectuent des corrélations canoniques pour leur propre compte comme une méthodologie statistique unique. Plus souvent, les corrélations canoniques sont trouvées et utilisées dans le contexte d’autres techniques (comme la MANOVA, l’analyse discriminante, etc.).