Un test t pour un échantillon unique est utilisé pour évaluer l’hypothèse nulle selon laquelle un échantillon que vous avez collecté provient d’une population ayant une moyenne spécifique. Par exemple, considérons les données hypothétiques suivantes de Denis (2016) sur les scores de QI :
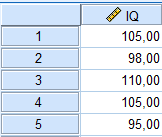
QI : 105, 98, 110, 105, 95
Cela signifie que le premier sujet a un QI de 105, le deuxième un QI de 98, etc. Supposons que vous souhaitiez savoir si un tel échantillon pourrait provenir d’une population ayant une moyenne de 100, qui est considérée comme le « QI moyen » sur de nombreux tests d’intelligence. La moyenne de l’échantillon est égale à 102,6, avec un écart-type de 6,02. La question que vous vous posez est la suivante :
Quelle est la probabilité d’obtenir une moyenne d’échantillon de 102,6 à partir d’une population avec une moyenne égale à 100 ?
Si la probabilité d’obtenir de telles données (102,6) est élevée sous l’hypothèse nulle que la moyenne de la population est égale à 100, alors vous n’avez aucune raison de douter de l’hypothèse nulle. Cependant, si cette probabilité est faible sous l’hypothèse nulle, il est peu probable qu’un tel échantillon provienne d’une population avec une moyenne égale à 100, et vous avez des preuves que l’échantillon provient probablement d’une autre population (peut-être une population de personnes avec un QI plus élevé).
Ainsi, nous formulons nos hypothèses nulle et alternative comme suit :
H0:μ=100
H1:μ≠100
où l’hypothèse nulle indique que la moyenne (μμ est le symbole pour la moyenne de la population) de QI est égale à 100 et l’hypothèse alternative indique que la moyenne de QI est différente de 100. Les inférences pour les tests sur un échantillon unique nécessitent généralement une distribution normale de la population ainsi que l’hypothèse d’indépendance. La normalité peut être vérifiée via des histogrammes ou d’autres graphiques, tandis que l’indépendance est généralement assurée par une méthode appropriée de collecte de données.
Nous entrons nos données dans SPSS comme suit :
ANALYSER→COMPARER LES MOYENNES→TEST T POUR ÉCHANTILLON UNIQUE
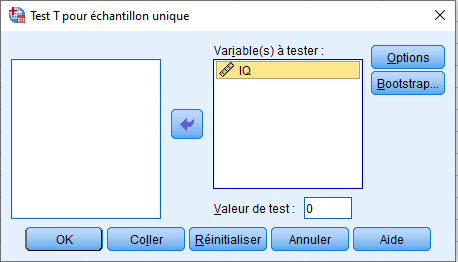
Nous déplaçons la variable QI sous Variables de test et spécifions une Valeur de test de 100 (la valeur sous l’hypothèse nulle) :
Si nous sélectionnons Options, nous obtenons :
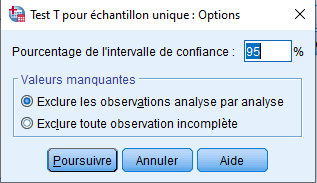
Par défaut, SPSS nous fournira un intervalle de confiance à 95% de la différence entre les moyennes (nous l’interpréterons dans nos résultats).
Lorsque nous exécutons le test, nous obtenons :

Nous interprétons les résultats :
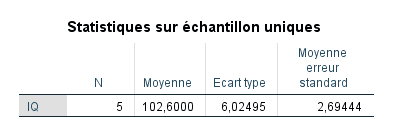
- SPSS nous donne le nombre d’observations dans l’échantillon (N=5), ainsi que la moyenne, l’écart-type et l’erreur standard estimée de la moyenne de 2,69, calculée comme :
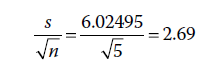
SPSS nous présente ensuite les résultats du test pour un échantillon unique :
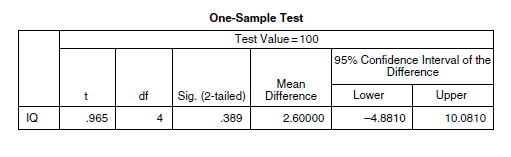
Nous interprétons :
- La valeur t obtenue est égale à 0,965, avec des degrés de liberté égaux au nombre d’observations moins un (soit 5−1=4).
- La valeur p bilatérale est égale à 0,389. Nous interprétons cela comme signifiant que la probabilité d’obtenir des données comme celles que nous avons obtenues si elles provenaient réellement d’une population avec une moyenne de 100 est p=0,389p=0,389. Comme ce nombre n’est pas inférieur à 0,05, nous ne rejetons pas l’hypothèse nulle. Autrement dit, nous n’avons pas de preuves suggérant que notre échantillon ne provient pas d’une population avec une moyenne de 100.
Un test t pour un échantillon unique a été effectué sur les données de QI pour évaluer l’hypothèse nulle selon laquelle ces données pourraient provenir d’une population avec un QI moyen de 100. Le test t n’a pas été statistiquement significatif (p=0,389p=0,389). Par conséquent, nous n’avons pas suffisamment de preuves pour douter que ces données pourraient provenir d’une population avec une moyenne égale à 100.
- SPSS nous fournit également la différence de moyenne, calculée comme 102,6 (moyenne de l’échantillon) moins 100,0 (moyenne de la population, valeur de test).
- Un intervalle de confiance à 95% de la différence est également fourni. Nous interprétons cela comme signifiant que dans 95% des échantillons tirés de cette population, nous nous attendrions à ce que la vraie différence de moyenne se situe entre −4,8810−4,8810 et 10,081010,0810. Notez que cet intervalle est centré sur la différence de moyenne obtenue de 2,60. Nous pouvons utiliser l’intervalle de confiance comme un test d’hypothèse. Toute valeur de population se trouvant en dehors de l’intervalle peut être rejetée avec p<0,05p<0,05. Notez que puisque l’intervalle contient la valeur de différence de population de zéro, cela suggère qu’une différence de moyenne de zéro est une valeur de paramètre plausible. Si zéro se trouvait en dehors de l’intervalle, cela suggérerait que la différence de moyenne dans la population n’est pas égale à 0, et nous pourrions rejeter l’hypothèse nulle selon laquelle la différence de moyenne de la population est égale à 0.
- Par conséquent, notre conclusion est que nous n’avons pas suffisamment de preuves pour rejeter l’hypothèse nulle. Autrement dit, nous n’avons pas de preuves pour douter que l’échantillon provient d’une population avec une moyenne égale à 100.