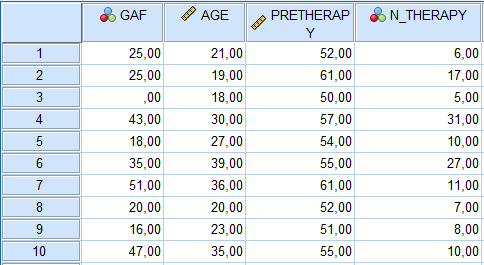
L’une des hypothèses de l’analyse de régression, qu’il s’agisse de régression linéaire simple ou multiple, est que les erreurs sont normalement distribuées. Pour examiner si cette hypothèse est au moins provisoirement satisfaite, nous pouvons effectuer des analyses des résidus sur notre modèle ajusté utilisant les variables AGE, PRETHERAPY et N_THERAPY pour prédire GAF. Un graphique de base des résidus pour le modèle peut être facilement obtenu en ouvrant la fenêtre ENREGISTRER(ANALYSE-REGRESSION-LINEAIRE-ENREGISTRER) dans la boîte de régression linéaire et en sélectionnant parmi plusieurs types de résidus :
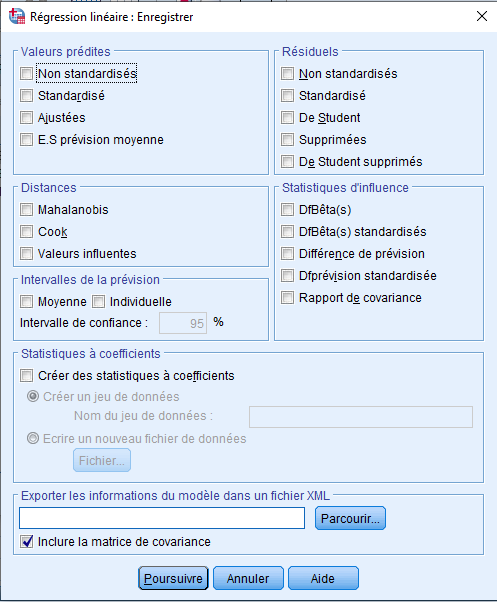
Lorsque nous ouvrons l’onglet SAVE, pour obtenir les résidus non standardisés, sélectionnez « Residuels (non standardisées) ».
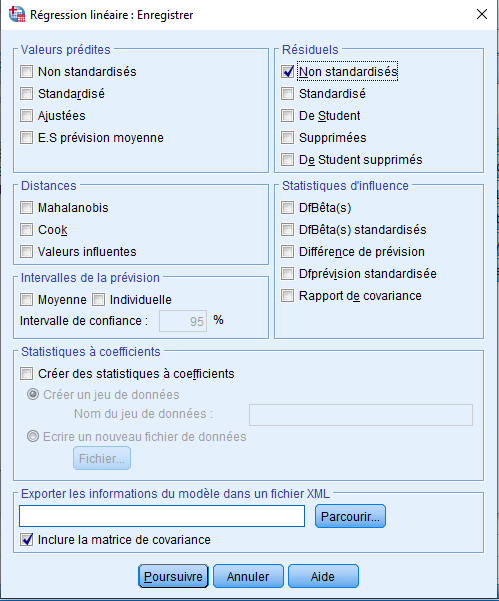
Typiquement, vous feriez cette sélection lors de la première analyse de régression, mais dans notre cas, nous avons choisi de le faire après coup car nous voulions d’abord interpréter les paramètres de notre modèle. Les résidus calculés apparaîtront dans la vue des données :
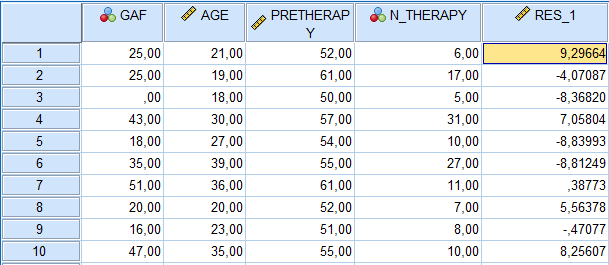
La colonne RES1 à droite ci-dessus contient les résidus calculés à partir de la régression. Vous pouvez vérifier que la somme des résidus est égale à 0.
Ensuite, en utilisant EXPLORER(ANALYSE-STATISTIQUES DESCRIPTIVES-EXPLORER), déplacez « Unstandardized Residuals » vers la liste des dépendantes
cliquez sur OK :
Nous notons les éléments suivants :
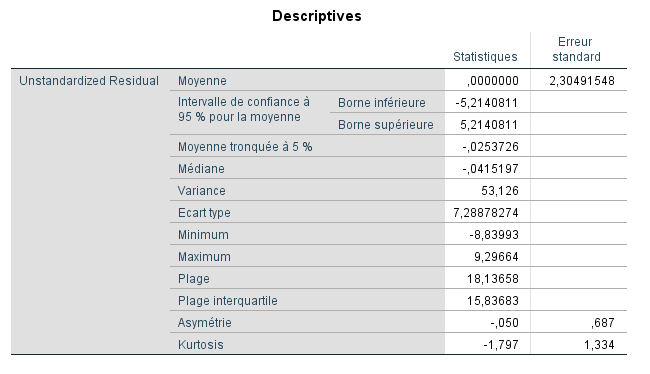
-
La moyenne des résidus non standardisés est égale à 0. C’est une nécessité, car les résidus représentent des écarts autour des valeurs prédites.
-
L’écart-type de 7,262 est l’écart-type des résidus mais avec le dénominateur habituel n−1. Par conséquent, il ne sera pas égal à l’erreur standard de l’estimation de 8,89 discutée précédemment dans le résumé du modèle, car cette estimation a été calculée comme la racine carrée de la somme des écarts carrés au numérateur divisée par 6 (c’est-à-dire n−k−1=10−3−1=6) pour notre modèle. Autrement dit, nous avons perdu k+1 degrés de liberté lors du calcul de l’écart-type des résidus pour notre modèle. La valeur de 7,26 présentée ci-dessus est l’écart-type des résidus avec seulement un degré de liberté perdu au dénominateur.
-
Nous pouvons voir à partir de la mesure d’asymétrie, égale à 0,001, que la normalité des résidus ne devrait pas poser problème (mais nous devrons tout de même les représenter graphiquement pour en être sûrs, car une asymétrie nulle peut également se produire dans des distributions bimodales).
-
Le graphique des résidus apparaît ci-dessous (un diagramme tige-feuille, un boxplot et un graphique Q-Q sont fournis). Bien que calculés sur un très petit échantillon, tous les graphiques ne nous donnent aucune raison de douter sérieusement que les résidus sont au moins approximativement normalement distribués (ces distributions sont plus rectangulaires que normales, mais avec un si petit échantillon dans notre cas, ce n’est pas suffisant pour rejeter les hypothèses de normalité – rappelez-vous, la vérification des hypothèses dans les modèles statistiques n’est pas une science exacte, surtout avec seulement 10 observations).
ANALYSER → STATISTIQUES DESCRIPTIVES → EXPLORER → TRACER
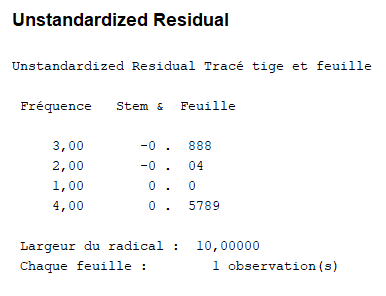
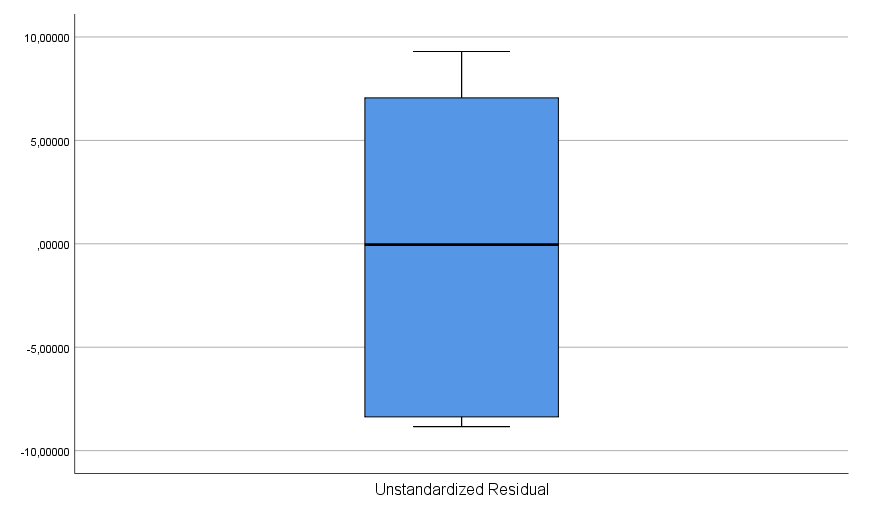
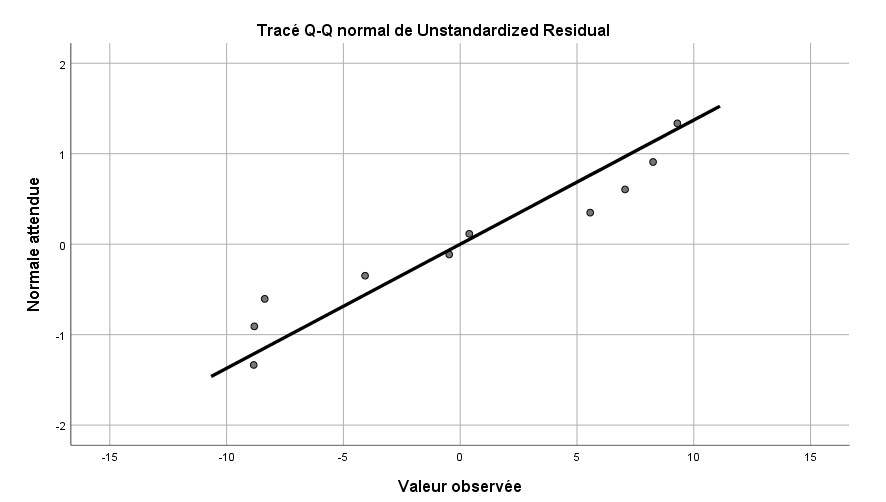

Les résidus non standardisés ont été examinés pour vérifier qu’ils sont au moins approximativement normalement distribués. Tous les graphiques suggèrent une distribution au moins approximativement normale, et les hypothèses nulles des tests de Kolmogorov-Smirnov et Shapiro-Wilk n’ont pas été rejetées, ce qui ne nous donne aucune raison de rejeter l’hypothèse.