Nous considérons les données fournies par Anderson (2003, p. 345) sur des crânes égyptiens. Dans cette analyse, il a été émis l’hypothèse que la taille du crâne est fonction de la période temporelle, également appelée « époque ». La taille du crâne est définie par quatre variables :
-
mb (largeur maximale du crâne)
-
bh (hauteur basi-brégmatique du crâne)
-
bl (longueur basio-alvéolaire du crâne)
-
nh (hauteur nasale du crâne)
Notez que ci-dessus nous avons abrégé nos variables comme nous les entrerons dans SPSS. C’est-à-dire que « mb » signifie « largeur maximale du crâne », « bh » signifie « hauteur basi-brégmatique du crâne », etc. Dans une ANOVA classique, nous pourrions analyser chacune de ces variables dépendantes séparément. Cependant, dans une MANOVA, nous choisissons de les analyser simultanément comme une combinaison linéaire du type :
mb + bh + bl + nh.
L’époque, la variable indépendante, a cinq niveaux : c4000BC, c3300BC, c1850BC, c200BC et cAD150.
Ainsi, notre énoncé de fonction pour la MANOVA ressemble à ceci :
mb + bh + bl + nh en fonction de l’eˊpoque (cinq niveaux).
Encore une fois, notez qu’il s’agit d’une MANOVA parce que nous avons plus d’une variable dépendante et que nous analysons ces variables simultanément. Rappelons qu’en théorie, nous pourrions simplement calculer quatre ANOVA univariées différentes qui considèrent chaque variable dépendante séparément dans chaque analyse. C’est-à-dire que nous aurions pu formuler quatre énoncés de fonction différents :
mb en fonction de l’eˊpoque.bh en fonction de l’eˊpoque.bl en fonction de l’eˊpoque.nh en fonction de l’eˊpoque.
Alors, pourquoi se donner la peine de calculer une MANOVA au lieu de plusieurs ANOVA ? Il y a deux raisons principales pour potentiellement préférer la MANOVA – la première est substantielle, et la seconde est statistique :
-
Premièrement, nous nous intéressons à l’analyse de quelque chose appelé « taille du crâne », qui est un concept multidimensionnel composé de mb, bh, bl et nh. C’est pourquoi il est logique dans ce cas de « combiner » toutes ces variables dépendantes en une somme. Si cela n’avait pas eu de sens théorique, alors effectuer une MANOVA n’aurait pas non plus eu beaucoup de sens. Par exemple, effectuer une MANOVA sur la combinaison linéaire suivante n’aurait aucun sens :
mb + bh + bl + pizza préférée en fonction de l’époque.
La MANOVA n’a pas de sens dans ce cas parce que « pizza préférée » n’appartient tout simplement pas substantivement à la combinaison linéaire. C’est-à-dire que mb + bh + bl + pizza préférée n’est plus « taille du crâne » ;
c’est autre chose (on ne sait pas trop quoi !). Le point important ici est que si vous envisagez de faire une MANOVA, c’est parce que vous avez plusieurs variables dépendantes à votre disposition qui, considérées comme une somme linéaire, ont du sens. Si cela n’a pas de sens, alors la MANOVA n’est pas quelque chose que vous devriez faire. Respectez la règle suivante :
Vous ne devriez pas faire une MANOVA simplement parce que vous avez plusieurs variables dépendantes à votre disposition pour l’analyse. Vous devriez faire une MANOVA parce que théoriquement, il est logique d’analyser plusieurs variables dépendantes en même temps.
-
La deuxième raison pour laquelle la MANOVA peut être préférée à plusieurs ANOVA séparées est de contrôler le taux d’erreur de type I. Rappelons que dans tout test statistique unique, il y a un taux d’erreur de type I, souvent fixé à 0,05. Chaque fois que nous rejetons une hypothèse nulle, nous le faisons avec la possibilité que nous puissions nous tromper. Cette possibilité est généralement fixée à 0,05. Eh bien, lorsque nous effectuons plusieurs tests statistiques, ce taux d’erreur se cumule et est approximativement additif (ce n’est pas tout à fait 0,05+0,05+0,05+0,05 dans notre cas, mais à peu près) ; Le point important pour nos besoins est que lorsque nous analysons des variables dépendantes simultanément, nous n’avons qu’un seul taux d’erreur à considérer au lieu de plusieurs comme nous aurions dans le cas de l’ANOVA. Ainsi, lorsque nous analysons la variable dépendante mb + bh + bl + nh, nous pouvons fixer notre niveau de signification à 0,05 et tester notre hypothèse nulle à ce niveau. Donc, en bref, une deuxième raison d’apprécier la MANOVA est qu’elle aide à contrôler l’inflation du taux d’erreur de type I. Cependant (et c’est important !), si la condition 1 ci-dessus n’est pas d’abord satisfaite, c’est-à-dire s’il n’a pas de sens « substantiel » que vous devriez faire une MANOVA, alors indépendamment du contrôle qu’elle a sur le taux d’erreur de type I, vous ne devriez pas faire de MANOVA ! La MANOVA doit d’abord avoir un sens substantiel du point de vue de la recherche avant que vous ne profitiez de ses avantages statistiques. Encore une fois, votre question de recherche devrait suggérer une MANOVA, pas seulement le nombre de variables dépendantes que vous avez dans votre ensemble de données.
Entrés dans SPSS, nos données se présentent comme suit (nous ne listons que 10 cas, tous pour epoch = -4000) :
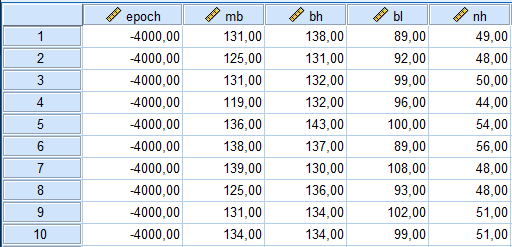
Nous procédons à l’exécution de la MANOVA : ANALYSER → MODÈLE LINÉAIRE GÉNÉRALE → MULTIVARIÉ
Nous déplaçons mb, bh, bl et nh vers la boîte Variables Dépendantes. Nous déplaçons epoch vers la boîte Facteur(s) Fixe(s). Si vous aviez une covariable à inclure, vous la déplaceriez vers la boîte Covariable(s).
Nous cliquons ensuite sur OK pour exécuter la MANOVA (nous sélectionnerons plus d’options plus tard).

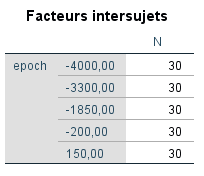
SPSS confirme d’abord pour nous qu’il y a N = 30 observations par groupe sur la variable indépendante. Le nombre total d’observations pour l’ensemble des données est de 150.
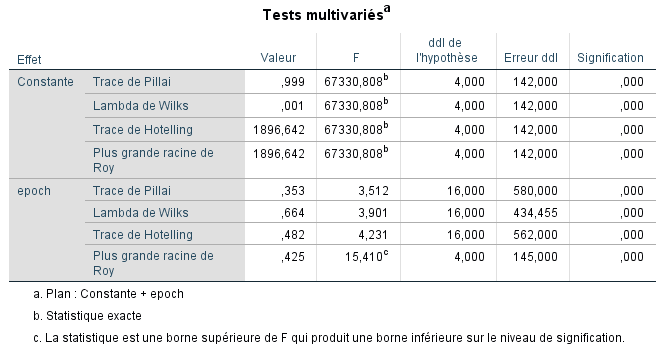
SPSS nous fournit ensuite les Tests Multivariés pour évaluer l’hypothèse nulle qu’il n’y a pas de différences moyennes à travers la combinaison linéaire des variables de réponse :
Une discussion de ces tests multivariés et de leur fonctionnement peut facilement prendre plusieurs pages et implique des matrices et des déterminants. Rappelons que dans l’ANOVA, nous n’avions généralement qu’un seul test de l’hypothèse nulle omnibus globale du type H0:μ1=μ2=μ3 pour disons un problème de population à trois groupes. Le seul test que nous utilisions pour tester l’effet global était le test F, défini comme
F=MS intergroupes/MS intragroupes
Ce qui fonctionnait bien et était notre seul test de l’effet global parce que nous n’avions qu’une seule variable dépendante. Dans le paysage multivarié, cependant, nous avons plus d’une variable dépendante, et donc tout test de la signification statistique globale de l’effet multivarié devrait prendre en compte les covariances entre les variables dépendantes. C’est précisément ce que font les tests multivariés de signification. Il y a généralement deux matrices d’intérêt en MANOVA – la matrice H, qui contient les différences moyennes entre les groupes, et la matrice E, qui contient les différences au sein des groupes. La matrice H est analogue à « intergroupes » dans l’ANOVA, et la matrice E est analogue à « intragroupes » dans l’ANOVA. Encore une fois, la raison pour laquelle nous avons besoin de matrices en MANOVA est parce que nous avons plus d’une variable dépendante, et les covariances entre les variables dépendantes sont également prises en compte dans ces matrices. Ayant défini (au moins conceptuellement) les matrices H et E, voici les quatre tests généralement rencontrés dans les résultats multivariés :
-
Lambda de Wilks :
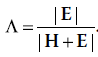 . Wilks est un critère inverse, ce qui signifie que si H est grand par rapport à E, Λ sera petit plutôt que grand. C’est-à-dire que si toute la variation est expliquée par H, alors
. Wilks est un critère inverse, ce qui signifie que si H est grand par rapport à E, Λ sera petit plutôt que grand. C’est-à-dire que si toute la variation est expliquée par H, alors 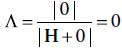 . S’il n’y a pas d’effet multivarié, alors H sera égal à 0, et donc
. S’il n’y a pas d’effet multivarié, alors H sera égal à 0, et donc 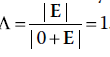 .
. -
Trace de Pillai :
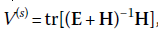 , où « tr » signifie « trace » de la matrice (qui est la somme des valeurs le long de la diagonale de la matrice). De quelle matrice prend-il la trace ? Notez q ue E + H = T, et donc ce que Pillai fait en réalité, c’est comparer la matrice H avec la matrice T. Donc, vraiment, nous aurions pu écrire Pillai de cette façon : V(s)=tr(H/T). Mais, parce que l’équivalent de la division en algèbre matricielle est de prendre l’inverse d’une matrice, nous l’écrivons plutôt comme . Pour faire court, contrairement à Wilks où nous voulions qu’il soit petit, Pillai est plus intuitif, en ce que nous voulons qu’il soit grand (comme nous le faisons avec le test F ordinaire de l’ANOVA). Nous pouvons aussi écrire Pillai en termes de valeurs propres :
, où « tr » signifie « trace » de la matrice (qui est la somme des valeurs le long de la diagonale de la matrice). De quelle matrice prend-il la trace ? Notez q ue E + H = T, et donc ce que Pillai fait en réalité, c’est comparer la matrice H avec la matrice T. Donc, vraiment, nous aurions pu écrire Pillai de cette façon : V(s)=tr(H/T). Mais, parce que l’équivalent de la division en algèbre matricielle est de prendre l’inverse d’une matrice, nous l’écrivons plutôt comme . Pour faire court, contrairement à Wilks où nous voulions qu’il soit petit, Pillai est plus intuitif, en ce que nous voulons qu’il soit grand (comme nous le faisons avec le test F ordinaire de l’ANOVA). Nous pouvons aussi écrire Pillai en termes de valeurs propres :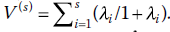 . Nous discutons des valeurs propres sous peu.
. Nous discutons des valeurs propres sous peu. -
Plus Grande Racine de Roy :
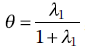 , où λ1 est simplement la plus grande des valeurs propres extraites. C’est-à-dire que Roy ne somme pas les valeurs propres comme le fait Pillai. Roy n’utilise que la plus grande des valeurs propres extraites.
, où λ1 est simplement la plus grande des valeurs propres extraites. C’est-à-dire que Roy ne somme pas les valeurs propres comme le fait Pillai. Roy n’utilise que la plus grande des valeurs propres extraites. -
Trace de Lawley-Hotelling :
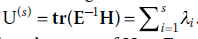 . Nous pouvons voir que U(s) prend la trace non pas de H à la matrice T mais plutôt la trace de H à E.
. Nous pouvons voir que U(s) prend la trace non pas de H à la matrice T mais plutôt la trace de H à E.
Il y a des chapitres entiers dans des livres et de nombreux articles de revues consacrés à la discussion des relations entre les différents tests multivariés de signification présentés ci-dessus. Pour nos besoins, nous allons droit au but et vous disons comment lire les résultats de SPSS et tirer une conclusion. Et en fait, souvent, la Trace de Pillai, le Lambda de Wilks, la Trace de Hotelling et la Plus Grande Racine de Roy suggéreront tous la même décision sur l’hypothèse nulle, celle de rejeter ou de ne pas rejeter. Cependant, il y a des moments où ils suggéreront des décisions différentes. Lorsque (et si) cela se produit, vous avez intérêt à consulter quelqu’un de plus familier avec ces tests pour obtenir des conseils sur ce qu’il faut faire. Nous pouvons voir que dans notre cas, tous les tests sont statistiquement significatifs. Cela est évident puisque dans la colonne Signif. toutes les valeurs p sont inférieures à 0,05 (nous pourrions même rejeter à 0,01 si nous le voulions).
Nous passons sur l’interprétation des tests pour l’Intercept, car elle a généralement peu de valeur pour nous. Nous interprétons les tests multivariés pour epoch :
-
Trace de Pillai = 0,353 ; puisque « Signif. » est inférieur à 0,05, rejeter l’hypothèse nulle.
-
Lambda de Wilks = 0,664 ; puisque « Signif. » est inférieur à 0,05, rejeter l’hypothèse nulle.
-
Trace de Hotelling = 0,482 ; puisque « Signif. » est inférieur à 0,05, rejeter l’hypothèse nulle.
-
Plus Grande Racine de Roy = 0,425 ; puisque « Signif. » est inférieur à 0,05, rejeter l’hypothèse nulle.
Par conséquent, notre conclusion est que sur une combinaison linéaire de mb, bh, bl et nh, nous avons des preuves de différences d’époque. Si nous considérons la combinaison linéaire de mb + bh + bh comme « taille du crâne », alors nous pouvons dire de manière provisoire que sur la « variable » dépendante de la taille du crâne, nous avons des preuves de différences moyennes.
Comment générer cette analyse dans IBM SPSS
Pour reproduire cette analyse dans IBM SPSS :
-
Préparation des données :
-
Organisez vos données avec une colonne pour la variable indépendante (epoch) et des colonnes pour chaque variable dépendante (mb, bh, bl, nh)
-
Assurez-vous que la variable epoch est codée comme variable nominale avec les 5 niveaux
-
-
Exécution de la MANOVA :
-
Allez dans le menu : Analyser → Modèle Linéaire Général → Multivarié
-
Dans la boîte de dialogue :
-
Sélectionnez mb, bh, bl et nh comme Variables Dépendantes
-
Sélectionnez epoch comme Facteur Fixe
-
Cliquez sur « Options » pour sélectionner les statistiques descriptives et les tests d’hypothèse
-
Cliquez sur « OK » pour exécuter l’analyse
-
-
-
Interprétation des résultats :
-
Vérifiez les tableaux « Facteurs Inter-Sujets » pour confirmer les effectifs
-
Examinez le tableau « Tests Multivariés » pour les quatre statistiques de test (Pillai, Wilks, Hotelling, Roy)
-
Vérifiez les valeurs p (colonne « Signif. ») pour déterminer la signification statistique
-
-
Options supplémentaires :
-
Pour des analyses post-hoc, cliquez sur le bouton « Post Hoc » et sélectionnez epoch
-
Pour des graphiques, cliquez sur le bouton « Graphiques » et configurez les diagrammes souhaités
-
Pour des statistiques supplémentaires, cliquez sur « Options » et sélectionnez les mesures souhaitées
-