Introduction
Lorsque nous parlons de la puissance d’un test statistique, nous faisons référence à sa capacité à détecter un effet si celui-ci est réellement présent dans la population. Pour illustrer cela, imaginez que vous êtes microbiologiste et que vous placez un échantillon de tissu sous un microscope pour détecter une souche virale. La détection ne sera possible que si votre microscope est suffisamment puissant. De même, en recherche statistique, vous avez besoin d’un test suffisamment puissant pour détecter un effet, comme une différence de moyenne entre deux groupes, si cette différence existe réellement.
Formellement, la puissance statistique se définit comme suit :
La puissance statistique est la probabilité de rejeter une hypothèse nulle sachant qu’elle est fausse.
Facteurs Influençant la Puissance Statistique
Plusieurs éléments contribuent à la puissance d’un test statistique :
- Taille de l’effet : Plus l’effet est grand, plus il est facile à détecter. Par exemple, dans un test de corrélation, une corrélation de 0,10 est plus difficile à détecter qu’une corrélation de 0,30.
- Variabilité de la population : Moins il y a de variabilité (ou « bruit ») dans la population, plus il est facile de détecter un effet. Cela revient à observer l’impact d’une pierre dans l’eau : c’est plus facile dans une eau calme que dans une eau agitée.
- Taille de l’échantillon : Plus la taille de l’échantillon est grande, plus la puissance statistique est élevée. Comme les chercheurs ont peu de contrôle sur la taille de l’effet ou la variabilité de la population, augmenter la taille de l’échantillon est souvent la méthode privilégiée pour améliorer la puissance.
Exemple avec G*Power : Estimation de la Taille d’Échantillon pour une Corrélation
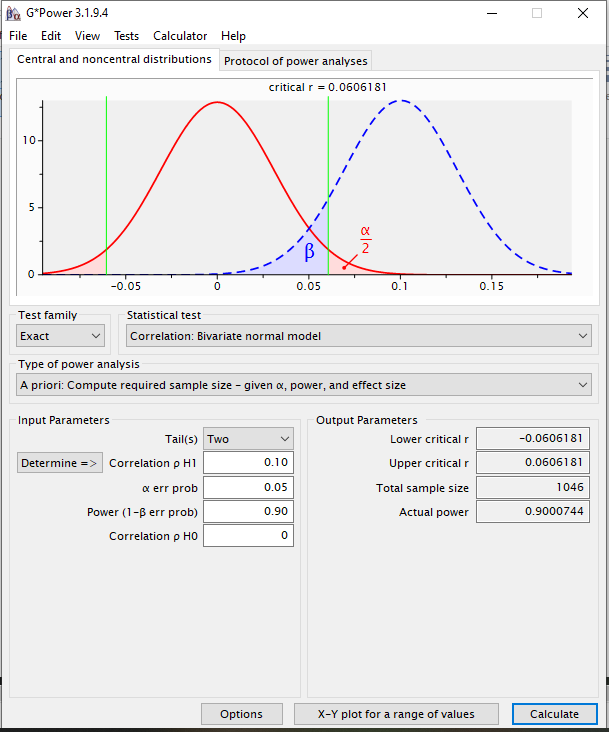
Prenons un exemple concret avec le logiciel GPower. Supposons que nous souhaitons estimer la taille d’échantillon nécessaire pour détecter une corrélation de Pearson de ρ=0,10 dans la population, avec un seuil de signification de 0,05 et une puissance de 0,90.
Voici les étapes dans GPower :
- Sélectionner un test bilatéral.
- Entrer la corrélation attendue sous l’hypothèse alternative (0,10).
- Définir le seuil de signification à 0,05.
- Fixer la puissance à 0,90.
- La corrélation sous l’hypothèse nulle est 0.
Résultat : Un échantillon d’environ 1046 participants est nécessaire pour atteindre une puissance de 0,90 dans ces conditions.
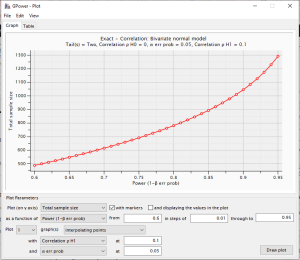
Courbes de Puissance
Les courbes de puissance montrent que pour une corrélation plus grande (par exemple, r=0,30), la taille d’échantillon requise diminue considérablement.
Puissance pour un Test d’Ajustement du Khi-deux
Pour un test d’ajustement du Khi-deux avec un effet moyen (w=0,30), une puissance de 0,95, un seuil de signification de 0,05 et 3 degrés de liberté, la taille d’échantillon estimée est de 191 sujets
Puissance pour un Test t à Échantillons Indépendants
Pour détecter une différence de moyenne correspondant à un d de Cohen de 0,50, avec un seuil de signification de 0,05 et une puissance de 0,95, la taille d’échantillon requise est de 105 participants par groupe
Puissance pour un Test t Apparié
Avec les mêmes paramètres que ci-dessus (effet d=0,50, seuil de 0,05, puissance de 0,95), un test t apparié ne nécessite qu’un échantillon total de 54 sujets. Cela montre l’avantage des plans appariés ou à mesures répétées : une puissance élevée avec un échantillon plus petit.
Conclusion
G*Power permet de réaliser des analyses de puissance pour une grande variété de tests statistiques.