Quelle a été la performance de nos fonctions discriminantes pour la classification ? Pour cela, nous pouvons demander à SPSS de nous fournir les résultats de classification. Les statistiques par cas accompagnées des résultats de classification nous donnent toutes les informations nécessaires pour savoir si l’analyse discriminante a réussi ou non à classer les observations :
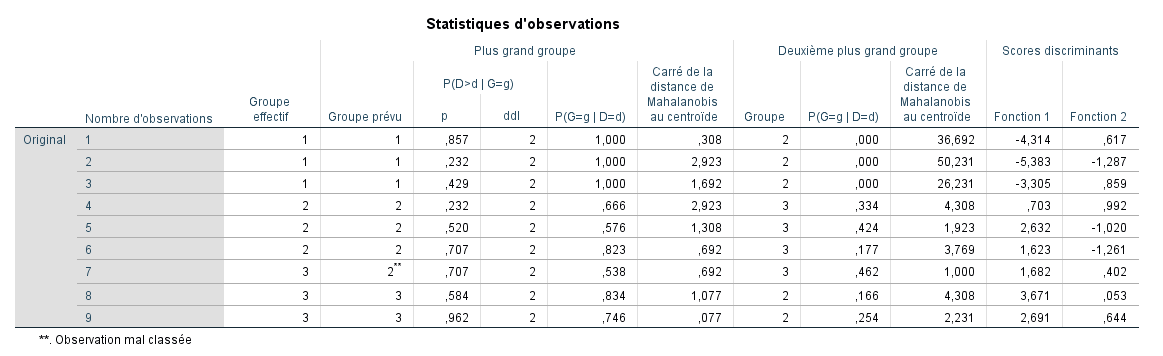
- Colonne 1 : contient le numéro de cas pour chaque observation. Nous avons un total de 9 observations.
- Colonne 2 : correspond au groupe réel auquel appartiennent les participants. Ce sont les groupes que nous avons saisis dans notre ensemble de données (il ne s’agit pas de valeurs de groupe prédites, mais bien de valeurs réelles d’appartenance).
- Colonne 3 : correspond au groupe prédit selon l’analyse discriminante. Comment les fonctions s’en sont-elles sorties ? Remarquez qu’elles ont correctement classé tous les cas sauf le cas n°7. Le cas 7 a été prédit dans le groupe 2 alors qu’en réalité il appartient au groupe 3. Il s’agit de la seule erreur de classification commise par la procédure.
- La distance de Mahalanobis au centroïde (au carré) représente une mesure de distance multivariée ainsi que la probabilité associée d’être classé dans le groupe donné. Remarquez que les deux colonnes de P(G = g|D = d) pour chaque cas (entre le groupe le plus probable et le deuxième plus probable) s’additionnent à 1,0. Si la distance par rapport au centroïde est très faible, la probabilité d’appartenir à ce groupe est élevée. Nous pouvons constater, pour les trois premiers cas, que la probabilité d’être classé dans le groupe donné en fonction de la distance est extrêmement élevée pour le groupe principal (1,000 ; 1,000 ; 1,000), et très faible pour le second groupe (0,000 ; 0,000 ; 0,000). Autrement dit, les cas 1 à 3 étaient des cas certains pour être classés dans le groupe 1 (le graphique des centroïdes que nous avons examiné précédemment le confirme facilement, puisque le groupe 1 est bien séparé des deux autres groupes).
- En examinant les autres cas, on remarque que si la distance entre le groupe le plus probable et le second est grande, alors la probabilité d’être classé dans ce groupe est plus faible que si la distance est faible.
- Les deux dernières colonnes sont les scores discriminants pour chaque fonction. Cette sortie du programme réplique les scores que nous avons déjà interprétés (et calculés pour quelques cas).
Bien que ces informations soient déjà contenues dans les statistiques par cas ci-dessus, SPSS fournit également un résumé des résultats de classification basé sur l’utilisation des fonctions discriminantes pour classer correctement les observations dans des groupes :
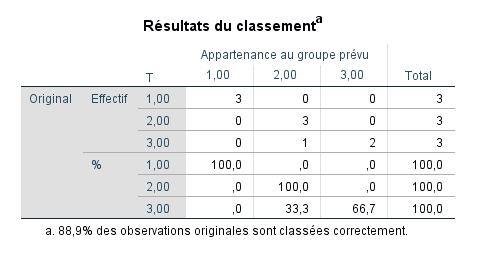
- Le mode de lecture du tableau consiste à lire chaque ligne :
- Pour les cas appartenant au groupe T = 1, le modèle a prédit que les 3 seraient dans le groupe T = 1.
- Pour les cas du groupe T = 2, le modèle a prédit que les 3 seraient dans le groupe T = 2.
- Pour les cas du groupe T = 3, le modèle a prédit que 2 seraient dans le groupe T = 3, mais un serait dans le groupe T = 2. Rappelons que d’après les statistiques par cas, c’est la seule erreur de prédiction.
- Les pourcentages en dessous des résultats de classification indiquent que :
- Pour les cas du groupe T = 1, le modèle prédit avec une précision de 100 %.
- Pour le groupe T = 2, également 100 %.
- Pour le groupe T = 3, une précision de 66,7 %.
- Le nombre de cas correctement classés est de 8 sur 9 cas possibles. C’est ce que révèle la note en bas du tableau : 8/9 soit 88,9 % des cas originaux ont été classés correctement.
- SPSS fournit toujours les résultats de classification, que l’on peut prendre tels quels, mais si vous souhaitez en savoir plus sur le fonctionnement interne de l’analyse discriminante, notamment pour les problèmes à deux groupes ou multi-groupes avec scores de coupure ou coefficients de classification, voir Hair et al. (2006), qui offrent une explication détaillée de ce que fait le programme « en arrière-plan », surtout dans les cas de nombres inégaux par groupe et/ou probabilités a priori inégales (dans notre exemple, nous avions des N égaux et des probabilités a priori égales).