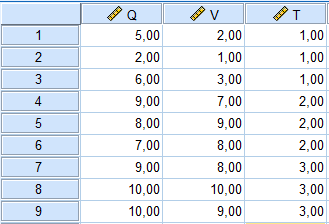
Nous considérons un exemple de MANOVA et d’analyse discriminante sur trois populations. Dans cet exemple, nous allons un peu au-delà des bases de ces procédures et présentons une variété de résultats fournis par SPSS, y compris une variété de coefficients générés par les fonctions discriminantes. Considérons une version des données de formation avec une variable de regroupement en trois catégories (1 = pas de formation, 2 = formation partielle, et 3 = formation approfondie) :
Entrées dans SPSS, nous obtenons :
Nous souhaitons d’abord exécuter la MANOVA sur la déclaration de fonction suivante :
Quantitatif + Verbal en fonction de la Formation
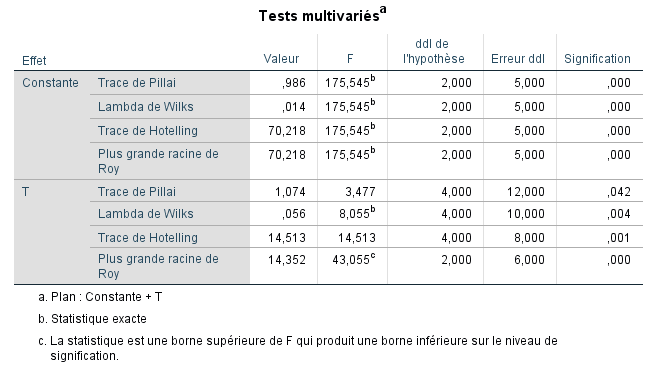
Tous les tests de signification multivariés suggèrent de rejeter l’hypothèse nulle multivariée (p < 0,05). Nous pouvons obtenir les valeurs propres pour notre MANOVA à l’aide de la syntaxe suivante :

La somme totale des valeurs propres est 14,35158 + 0,16124 = 14,51282. La première fonction discriminante est très importante, car 14,35158/14,51282 = 0,989. La deuxième fonction discriminante est beaucoup moins importante, car 0,16124/14,51282 = 0,01. Lorsque nous élevons au carré la corrélation canonique de 0,96688 pour la première fonction, nous obtenons 0,935, ce qui signifie qu’environ 93 % de la variance est expliquée par cette première fonction. Lorsque nous élevons au carré la corrélation canonique de 0,37263, nous obtenons 0,139, ce qui signifie qu’environ 14 % de la variance est expliquée par cette deuxième fonction discriminante. Rappelons que nous aurions pu également obtenir ces corrélations canoniques au carré par 14,35158/(1 + 14,35158) = 0,935 et 0,16124/(1 + 0,16124) = 0,139.
Nous obtenons maintenant l’analyse discriminante correspondante sur ces données et comparons les valeurs propres avec celles de la MANOVA, ainsi que des résultats plus informatifs – ANALYSER → CLASSIFIER → ANALYSE DISCRIMINANTE
Nous pouvons voir que les valeurs propres et les corrélations canoniques pour chaque fonction discriminante correspondent à celles obtenues via la MANOVA dans SPSS. Nous voyons également que le Lambda de Wilks pour les fonctions 1 à 2 est statistiquement significatif (p = 0,003). La deuxième fonction discriminante n’est pas statistiquement significative (p = 0,365).
SPSS nous fournit également les coefficients non standardisés des fonctions discriminantes (à gauche), ainsi que la constante pour le calcul des scores discriminants. À droite se trouvent les coefficients standardisés (généralement recommandés pour interpréter l' »importance » relative des variables composant la fonction).
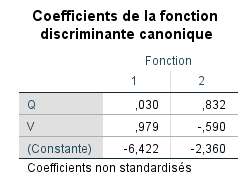

Nous interprétons ces coefficients plus en détail :
-
Coefficients non standardisés – analogues aux poids de régression partielle bruts en régression. La valeur constante de -6,422 est l’intercept pour le calcul des scores discriminants. Pour la fonction 1, le calcul est :
Y=−6,422+0,030(Q)+0,979(V).
Pour la fonction 2 :
Y=−2,360+0,832(Q)−0,590(V). -
Coefficients standardisés – analogues aux coefficients Beta standardisés en régression multiple. Ils peuvent être utilisés comme mesure de l’importance de chaque variable dans la fonction discriminante. Nous voyons que pour la fonction 1, « Verbal » contribue fortement.
-
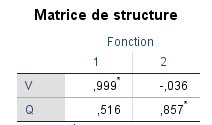
Matrice de structure – corrélations bivariées entre les variables et la fonction discriminante. Rencher (1998) met en garde contre une interprétation trop basée sur ces coefficients, car ils représentent une contribution univariée plutôt que multivariée. Interpréter les coefficients standardisés est souvent préférable, mais examiner les deux types de coefficients peut être informatif pour « trianguler » la nature des dimensions extraites.
Nous pouvons voir qu’à travers tous les coefficients, « Verbal » est plus pertinent pour la fonction 1, tandis que « Quantitatif » est plus pertinent pour la fonction 2. Nous ne montrons pas le test de Box’s M pour ces données car nous l’avons déjà démontré auparavant. Essayez-le vous-même et vous constaterez qu’il n’est pas statistiquement significatif (p = 0,532), ce qui signifie que nous n’avons aucune raison de douter de l’hypothèse d’égalité des matrices de covariance.
Deux fonctions discriminantes ont été extraites, la première affichant une mesure d’association élevée (corrélation canonique au carré de 0,935), qui s’est avérée statistiquement significative (Lambda de Wilks = 0,056, p = 0,003). Les coefficients des fonctions discriminantes canoniques et leurs homologues standardisés ont tous deux suggéré que « Verbal » était plus pertinent pour la fonction 1 et « Quantitatif » pour la fonction 2. Les coefficients de structure ont également attribué un schéma d’importance similaire. Les scores discriminants ont été obtenus et tracés, révélant que la fonction 1 fournissait une bonne discrimination entre les groupes 1 vs. 2 et 3, tandis que la deuxième fonction fournissait un pouvoir discriminant minimal.
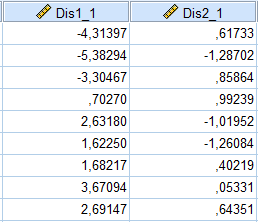
Comment chaque colonne a-t-elle été calculée ? Elles ont été calculées à l’aide des coefficients non standardisés. Calculons quelques scores pour la première et la deuxième fonction :
Fonction 1, cas 1 :
−6,422+5(0,030)+2(0,979)=−6,422+0,15+1,958=−4,314
Fonction 1, cas 2 :
−6,422+2(0,030)+1(0,979)=−6,422+0,06+0,979=−5,383
Fonction 2, cas 1 :
−2,360+5(0,832)+2(−0,590)=−2,360+4,16−1,18=0,617
Fonction 2, cas 2 :
−2,360+2(0,832)+1(−0,590)=−2,360+1,664−0,590=−1,287
Nous pouvons voir que nos calculs correspondent à ceux générés par SPSS pour les deux premiers cas de chaque fonction.
SPSS nous fournit également les centroïdes des groupes (moyennes) :
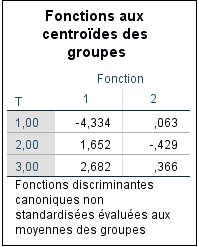
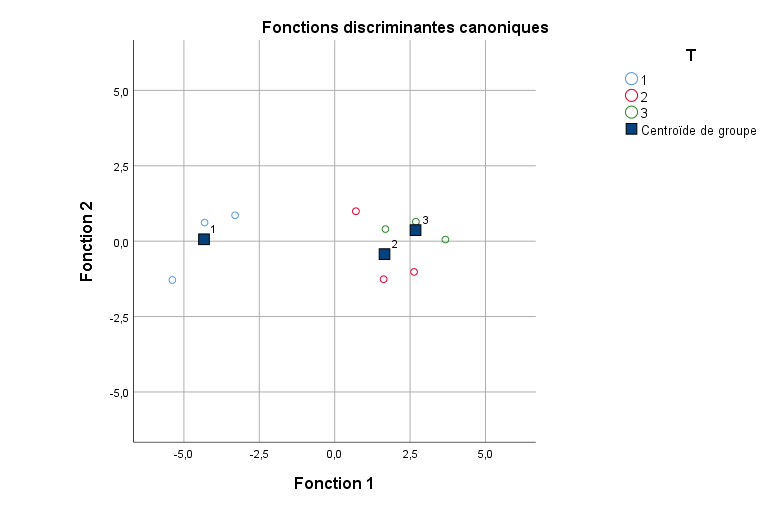
Pour apprécier ces valeurs, considérons le graphique généré par SPSS :
-
Fonction 1 :
-
Moyenne des scores pour T=1 : (confirmé par −4,31397,−5,38294,−3,30467).
-
Moyenne pour T=2 : 1,652 (confirmé par 0,70270,2,63180,1,62250).
-
Moyenne pour T=3: 2,682 (confirmé par 1,68217,3,67094,2,69147.
-
-
Fonction 2 :
-
T=1 : [0,61733+(−1,28702)+0,85864]/3=0,063.
-
T=2: [0,99239+(−1,01952)+(−1,26084)]/3=−0,429.
-
T=3: [0,40219+0,05331+0,64351]/3=0,366.
-
Nous pouvons obtenir plus de détails sur les valeurs réelles dans le graphique en demandant à SPSS d’étiqueter chaque point (double-cliquez sur les points du graphique pour afficher les étiquettes).
Remarquez que SPSS étiquette les valeurs des données dans le graphique selon leur valeur sur la fonction 2 (axe y). En rappelant les scores discriminants pour la fonction 2, nous pouvons facilement les faire correspondre.