Le domaine de la vérification des hypothèses et de la détection des valeurs aberrantes est vaste. Les experts consacrent leur carrière à développer de nouvelles méthodes pour identifier les observations multivariées éloignées des autres. La théorie sous-jacente est très complexe (pour plus de détails, voir Fox (2016)). Pour nos besoins, nous allons directement à l’essentiel et fournissons des directives immédiates pour détecter les observations qui pourraient avoir une influence importante sur le modèle de régression ou qui sont multivariées « anormales » au point d’être considérées comme des valeurs aberrantes. Nous utilisons le terme « influence importante » dans notre contexte uniquement pour indiquer les observations qui pourraient, en général, avoir un « effet » significatif sur les estimations des paramètres du modèle. Dans des traitements plus théoriques des diagnostics de régression, des définitions précises sont données pour diverses manières dont les observations peuvent exercer une influence ou avoir un impact.
Nous allons demander à SPSS les distances de Mahalanobis, les valeurs de Cook’s d et les leviers :
ANALYSE → REGRESSION → LINEARE → ENREGISTRER
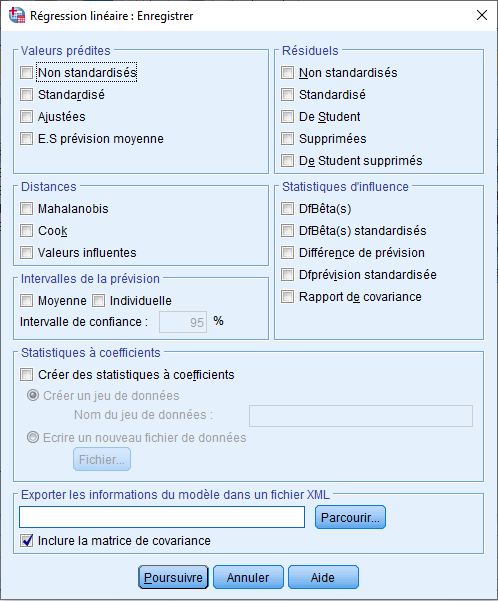
Une fois dans l’option ENREGISTRER, cochez Mahalanobis, Cook et les valeurs influentes. Le résultat de ces sélections est affiché dans la vue des données :
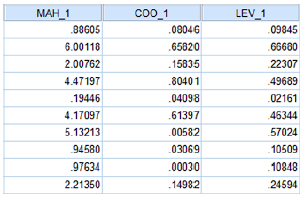
Pour des raisons pratiques, voici les règles empiriques à connaître :
-
Mahalanobis (MAH_1) : les valeurs sont considérées comme « élevées » si elles dépassent une valeur critique calculée à partir d’une distribution d’échantillonnage du Chi-degrés de liberté égaux au nombre de prédicteurs. Pour nos données, avec trois prédicteurs à 0.05, cette valeur est de 7.82 (16.27 si vous utilisez 0.001). Bien que l’observation 2 dans nos données (MAH_1 = 6.00118) soit relativement élevée, elle ne remplit pas les critères pour être considérée comme une valeur aberrante multivariée.
-
Cook’s d (COO_1) : des valeurs supérieures à 1.0 peuvent suggérer que l’observation exerce une influence assez forte sur les coefficients de régression estimés. Les seuils exacts ne sont pas obligatoires – recherchez les valeurs qui se distinguent des autres. Cook’s d nous donne une mesure de l’impact d’une observation donnée sur la solution finale, en évaluant dans quelle mesure les résultats changeraient si l’analyse était refaite sans cette observation.
-
Leviers (LEV_1) : ce sont les valeurs de levier. Les valeurs de levier supérieures à deux fois la moyenne peuvent être préoccupantes. Pour nos données, la moyenne est de 0.3 (vérifiez avec DESCRIPTIVES), donc le seuil général est de 0.6 (c’est-à-dire 2 fois 0.3), ce que l’observation 2 dépasse. Le levier est une mesure de l’écart d’une observation par rapport à la moyenne des prédicteurs. Les seuils ne font pas l’objet d’un consensus .