Nous examinons la procédure d’analyse de variance, généralement désignée par l’acronyme ANOVA. Rappelons que dans le test t, nous évaluions des hypothèses nulles du type H0 : μ1=μ2 contre des hypothèses alternatives statistiques du type H1 : μ1≠μ2. Ces tests t pour échantillons indépendants comparaient les moyennes de deux groupes. Mais que faire si nous avions plus de deux groupes à comparer ? Et si nous en avions trois ou plus ? C’est là qu’intervient l’ANOVA.
Dans l’ANOVA, nous évaluerons des hypothèses nulles du type H0:μ1=μ2=μ3 contre une hypothèse alternative selon laquelle il existe une différence quelque part entre les moyennes (par exemple, H1:μ1≠μ2=μ3). Ainsi, à cet égard, l’ANOVA peut être considérée comme une extension du test t pour échantillons indépendants, ou inversement, le test t peut être interprété comme un « cas particulier » de l’ANOVA.
Prenons un exemple pour illustrer la procédure ANOVA. Considérons les données sur la réussite scolaire tirées de Denis (2016) :
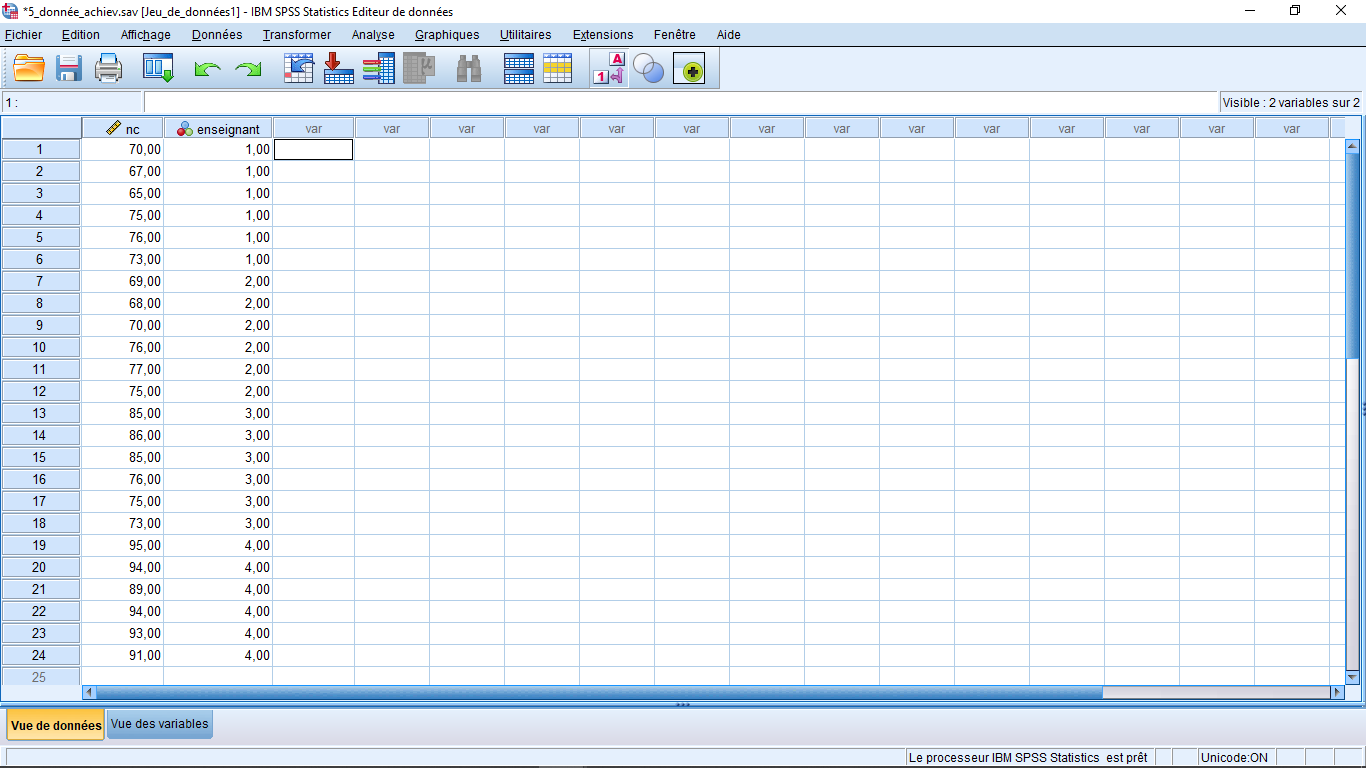
La réussite en fonction de l’enseignant
Bien que nous puissions constater que les moyennes d’échantillon diffèrent selon l’enseignant, la question qui nous intéresse est de savoir si ces différences entre les groupes sont suffisantes pour suggérer une différence entre les moyennes de la population. Un résultat statistiquement significatif (par exemple, p<0.05) indiquerait que l’hypothèse nulle H0:μ1=μ2=μ3=μ4 peut être rejetée en faveur d’une hypothèse alternative selon laquelle il existe une différence quelque part entre les moyennes de la population (mais nous ne saurons pas où se situent ces différences sans effectuer des contrastes ou des tests post hoc, dont nous parlerons plus tard). Dans cette expérience, nous ne nous intéressons qu’à généraliser les résultats à ces enseignants spécifiques inclus dans l’étude, et non à d’autres dans la population.
Cette approche donne lieu à ce que l’on appelle le modèle ANOVA à effets fixes (nous opposerons cela plus tard au modèle ANOVA à effets aléatoires). Les inférences dans l’ANOVA à effets fixes reposent sur des hypothèses de normalité (au sein de chaque niveau de la variable indépendante), d’indépendance et d’homogénéité des variances (entre les niveaux de la variable indépendante). Nous organisons nos données dans SPSS comme indiqué précédemment.
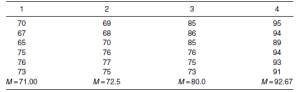
Pour avoir une première idée de ces données, nous pouvons obtenir quelques statistiques descriptives via la fonction EXPLORE par niveaux du facteur enseignant :
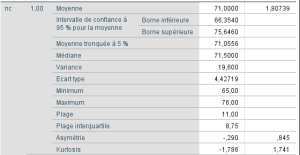
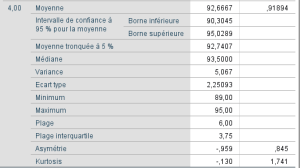
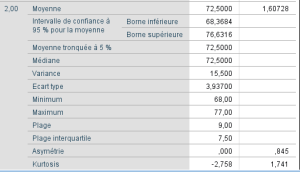
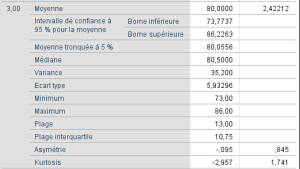
Ces statistiques descriptives nous donnent une idée de la distribution des scores de réussite (nc) pour les différents niveaux de enseignement.
Remarque : Les espaces laissés vides sont destinés à accueillir des tableaux, graphiques ou images qui pourraient accompagner le texte original. Les données et les résultats statistiques ont été conservés tels quels pour assurer la fidélité à l’article original.