Considérons les données suivantes tirées de Denis (2016) :
| Données hypothétiques sur les capacités quantitatives et verbales pour ceux recevant une formation (Groupe = 1) versus ceux ne recevant pas de formation (Groupe = 0) |
|---|
| Sujet | Quantitatif | Verbal | Groupe de formation |
| 1 | 5 | 2 | 0 |
| 2 | 2 | 1 | 0 |
| 3 | 6 | 3 | 0 |
| 4 | 9 | 7 | 0 |
| 5 | 8 | 9 | 0 |
| 6 | 7 | 8 | 1 |
| 7 | 9 | 8 | 1 |
| 8 | 10 | 10 | 1 |
| 9 | 10 | 9 | 1 |
| 10 | 9 | 8 | 1 |
Ces données comprennent des scores quantitatifs et verbaux pour 10 participants, dont la moitié a suivi un programme de formation (codé 1), tandis que l’autre moitié ne l’a pas suivi (codé 0). Nous souhaitons savoir si les scores quantitatifs et verbaux permettent de prédire à quel groupe de formation un participant appartient. Notre variable réponse est le groupe de formation (T), tandis que nos prédicteurs sont les scores quantitatifs (Q) et verbaux (V).
Nous entrons les données dans SPSS comme suit :
Pour effectuer la régression logistique dans SPSS, nous sélectionnons :
ANALYSE → RÉGRESSION → LOGISTIQUE BINAIRE
Nous déplaçons Q dans la boîte des covariables et T dans la boîte des variables dépendantes. Nous nous assurons que la méthode « EntreZ » est sélectionnée. Cliquez sur OK pour exécuter la procédure.

Nous sélectionnerons plus d’options plus tard. Pour l’instant, nous exécutons l’analyse pour voir les principaux coefficients de sortie de la régression logistique et discutons de leur interprétation différente par rapport à celle de la régression des moindres carrés ordinaires :
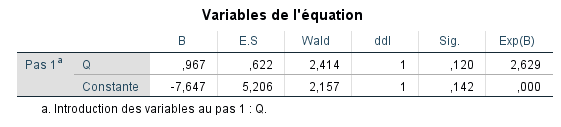
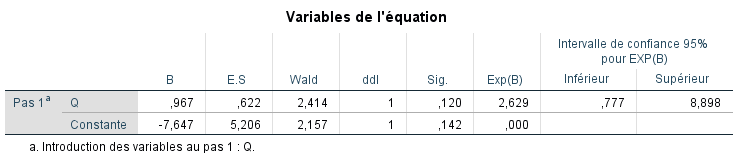
Nous ignorons le terme constant et passons directement à l’interprétation de l’effet pour Q. Notez que la valeur de B est égale à 0,967 et n’est pas statistiquement significative (p = 0,120). Pour l’instant, nous nous intéressons surtout à discuter de son interprétation et de sa différence par rapport aux coefficients de la régression des moindres carrés ordinaires. Rappelons comment nous interpréterions B = 0,967 dans un problème de régression ordinaire :
Pour une augmentation d’une unité de Q, nous nous attendrions, en moyenne, à une augmentation de 0,967 unité de la variable dépendante.
Cette interprétation est incorrecte pour une régression logistique, car notre variable dépendante n’est pas une variable continue. Elle est binaire. Il n’a guère de sens de dire que nous nous attendons à une augmentation de 0,967 d’une variable dépendante lorsque cette variable ne peut prendre que deux valeurs : formation = 1 vs formation = 0. Nous devons interpréter le coefficient différemment. Dans la régression logistique, le coefficient 0,967 est en réalité exprimé en unités de quelque chose appelé le logit, qui est le log des cotes. Qu’est-ce que cela signifie ? Nous le découvrirons dans un instant. Pour l’instant, il suffit de savoir que l’interprétation correcte du coefficient est la suivante :
Pour une augmentation d’une unité de Q, nous nous attendrions, en moyenne, à une augmentation de 0,967 unité du logit de la réponse.
Cette interprétation, bien que correcte, a peu de sens intuitif car les « logits » sont difficiles à interpréter seuls. Comme mentionné, les logits sont le log des cotes (généralement le log naturel, ln, c’est-à-dire en base e), où les cotes d’un événement sont définies comme le rapport entre la probabilité que l’événement se produise et 1 moins cette probabilité :
cotes = p/(1-p)
Prendre le log naturel transforme les cotes en quelque chose d’approximativement linéaire, ce qui est le logit mentionné précédemment. Les logits sont malaisés à interpréter, mais heureusement, nous pouvons les retransformer en cotes par une simple transformation qui consiste à exponencier le logit comme suit :
![]()
Dans cette transformation, le nombre 0,967 est le coefficient du logit obtenu à partir de la régression logistique, et l’exposant p sur 1-p représente les cotes. Ainsi, le log naturel des cotes est la partie ln(p/1-p). Lorsque nous exponencions ce coefficient en base e, qui est la fonction exponentielle égale à environ 2,718, nous retrouvons les cotes, et le nombre 2,63 s’interprète comme suit :
Pour une augmentation d’une unité de Q, les cotes d’être dans le groupe 1 par rapport au groupe 0 sont, comme attendu, de 2,63 contre 1.
Que signifie cela ? Si Q n’avait aucun effet, alors pour une augmentation d’une unité de Q, les cotes d’être dans le groupe 1 par rapport au groupe 0 seraient de 1 contre 1, et nous obtiendrions un logit de 0. Le fait qu’elles soient de 2,63 contre 1 signifie qu’à mesure que Q augmente d’une unité, la chance d’être dans le groupe 1 par rapport au groupe 0 est également plus grande. Le nombre 2,63 dans ce contexte est souvent appelé rapport de cotes. Si les cotes avaient été inférieures à 1 contre 1, alors une augmentation de Q suggérerait une diminution de la chance d’être dans le groupe 1 par rapport au groupe 0. Comme les cotes sont centrées sur 1,0, nous pouvons également interpréter le nombre 2,63 de la manière équivalente suivante :
Pour une augmentation d’une unité de Q, les cotes sont, comme attendu, 2,63 fois plus grandes d’être dans le groupe 1 par rapport au groupe 0, ce qui se traduit par une augmentation de 163 %. Autrement dit, une augmentation d’une unité de Q multiplie les cotes d’être dans le groupe 1 par 2,63.
Pour référence, des cotes de 2 représenteraient une augmentation de 100 % (puisque 2 est le double de 1). Mais comme les logits, les cotes sont difficiles à interpréter (sauf si vous êtes un parieur ou que vous misez sur des courses de chevaux !). Heureusement encore, nous pouvons transformer les cotes d’abord en un logit prédit, puis l’utiliser pour transformer cela en une probabilité, ce qui est beaucoup plus intuitif pour la plupart d’entre nous. À titre d’exemple, calculons d’abord le logit prédit yi‘ pour quelqu’un ayant un score de 5 en quantitatif. Rappelons que la constante dans notre sortie SPSS était égale à -7,647, donc notre équation estimée pour prédire le logit de quelqu’un ayant un score de 5 en quantitatif est la suivante :
yi‘ = -7,647 + 0,967(q_i)
= -7,647 + 0,967(5)
= -2,81
Assurez-vous de savoir d’où viennent ces termes : -7,647 est la valeur de la constante dans l’équation estimée de notre sortie (c’est-à-dire l’ordonnée à l’origine de l’équation), et 0,967 est le coefficient associé à Q. L’équation indique que le logit prédit de quelqu’un ayant Q = 5 est -2,81. Mais encore une fois, il s’agit d’un logit, quelque chose de difficile à interpréter. Convertissons ce logit en une probabilité par la transformation suivante :
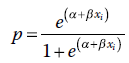
où α + βxi est le logit prédit obtenu en utilisant l’équation du modèle estimé à partir de la régression logistique. Pour Q = 5, nous avons :
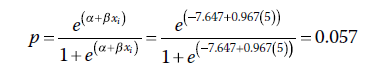
Cela signifie que pour quelqu’un ayant un score Q de 5, la probabilité prédite d’être dans le groupe = 1 est égale à 0,057. Et pour quelqu’un ayant un score de 10 en Q ? La probabilité prédite est :
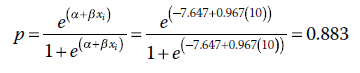
Autrement dit, pour quelqu’un ayant un score de 10 en capacité quantitative, la probabilité prédite d’être dans le groupe ayant reçu la formation (c’est-à-dire groupe = 1) est égale à 0,883. Nous pouvons continuer à calculer les logits et probabilités prédits pour toutes les valeurs de Q, de manière conceptuellement analogue à la façon dont nous calculons les valeurs prédites dans la régression des moindres carrés ordinaires.
Examinons maintenant une partie du reste de la sortie générée par SPSS pour la régression logistique, mais d’abord, nous demanderons quelques options supplémentaires. Sous Régression logistique : Options, cochez Tracés de classification, Historique des itérations, et CI pour exp(B) à 95 %.
Cliquez sur poursuivre, puis exécutez la régression logistique.
SPSS génère d’abord pour nous un Résumé du traitement des cas nous informant du nombre de cas inclus dans l’analyse. Pour nos données, nous avons inclus les 10 cas. SPSS nous montre également le Codage de la variable dépendante, qui nous indique quelles valeurs ont été attribuées aux nombres de la variable dépendante. Pour nos données, 0 = 0 et 1 = 1, et nous modélisons les valeurs « 1 » (c’est-à-dire la probabilité d’être dans le groupe de formation) :


SPSS nous donne ensuite la première étape de l’ajustement du modèle, qui consiste à ajuster le modèle avec seulement le terme constant. SPSS appelle cela Bloc 0 :
Bloc 0 : Bloc initial
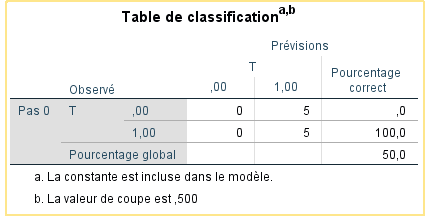

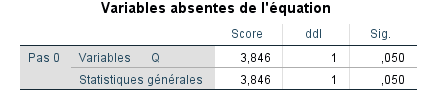
Nous n’interprétons pas ce qui précède, car cela n’inclut pas notre prédicteur Q. Cette sortie nous indique simplement comment notre modèle se comporte sans avoir Q. Il y a cinq observations dans chaque groupe, et le modèle dit qu’il peut classer correctement 50 % des cas. Le modèle fera-t-il mieux une fois que nous aurons inclus Q ? Voyons cela.
Interprétons maintenant le Bloc 1, dans lequel Q a été introduit dans le modèle :
Bloc 1 : Méthode = Entrer
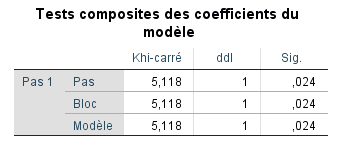

SPSS nous donne une valeur du Chi carré pour le modèle de 5,118, avec une valeur p associée de 0,024. Il s’agit d’une mesure globale de l’ajustement du modèle, nous indiquant que l’introduction du prédicteur Q nous aide à mieux prédire que le hasard seul (c’est-à-dire sans avoir le prédicteur dans le modèle) puisque p < 0,05. Nous n’avons qu’une seule « étape » car nous n’effectuons pas de régression hiérarchique ou pas à pas.
Les statistiques du résumé du modèle sont interprétées comme suit :
-
La statistique -2 Log-vraisemblance de 8,745 peut être utilisée pour comparer l’ajustement de modèles imbriqués, ce qui dépasse le cadre de ce chapitre. Pour plus de détails, voir Fox (2016). Pour nos besoins, nous n’avons pas à nous préoccuper de cette valeur.
-
La valeur R² de Cox & Snell de 0,401 est une mesure pseudo-R², cependant, contrairement au R² dans la régression des moindres carrés, elle n’a pas une valeur maximale de 1,0. Par conséquent, nous devons hésiter à l’interpréter comme une statistique de « variance expliquée » comme nous le ferions pour un R² ordinaire. Néanmoins, des valeurs plus grandes qu’autrement indiquent généralement que le modèle s’ajuste mieux qu’autrement.
-
La mesure R² de Nagelkerke est une autre mesure pseudo-R², cependant, comme celle de Cox & Snell, elle n’a pas une interprétation naturelle de « variance expliquée ». Cependant, comme celle de Cox & Snell, des valeurs plus grandes qu’autrement sont généralement indicatives d’un meilleur ajustement du modèle. Ces deux statistiques, le R² de Cox & Snell et le R² de Nagelkerke, sont utiles comme mesures approximatives de la qualité de l’ajustement du modèle, mais ne doivent pas être « surinterprétées » comme si elles étaient des mesures d’ajustement de modèle similaires à celles de la régression OLS. Ne les interprétez pas strictement comme des statistiques de « variance expliquée ». L’indice de Nagelkerke corrige celui de Cox & Snell pour avoir une valeur maximale de 1,0 (voir Cohen et al. (2003) pour plus de détails).
Ensuite, SPSS nous fournit les coefficients du modèle et le tableau de classification mis à jour basé sur l’inclusion de Q dans le modèle :
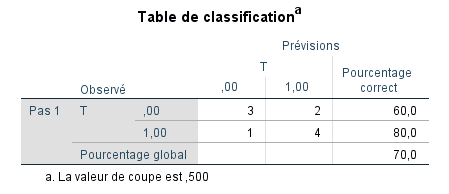
Le tableau de classification nous indique que 70 % des cas sont maintenant correctement classés sur la base du modèle de régression logistique utilisant Q comme prédicteur. Nous pouvons également conclure ce qui suit :
-
Pour les casdu groupe = 0, 60 % des cas ont été correctement classés (3 sont allés au groupe 0 ; 2 sont allés au groupe 1).
-
Pour les cas du groupe = 1, 80 % des cas ont été correctement classés (1 est allé au groupe 0 ; 4 sont allés au groupe 1).
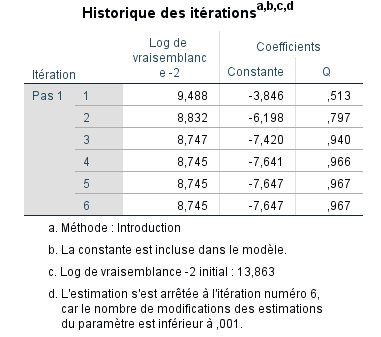
SPSS nous montre l’historique des itérations que nous avons demandé. Cela ne s’appliquera pas directement à la rédaction de vos résultats de recherche, mais il montre combien d’itérations ont été nécessaires pour converger essentiellement vers des coefficients estimés. Pour nos données, l’estimation s’est terminée à l’itération numéro 6.
La sortie Variables dans l’équation (à côté du tableau de classification) nous donne les informations que nous avons discutées plus tôt lors de l’introduction de la façon d’interpréter la sortie de la régression logistique. Rappelons que celles-ci sont maintenant en unités de logit, donc notre logit prédit pour une valeur donnée de Q est estimé par l’équation :
yi‘ = -7,647 + 0,967(qi)
Rappelons également que lorsque nous exponencions le logit, nous obtenons le nombre de cotes (Exp(B)) de 2,629 (souvent appelé rapport de cotes dans ce contexte). Nous pouvons également demander à SPSS de générer les probabilités prédites d’appartenance au groupe pour chaque observation de nos données. Nous cochons Probabilités et Groupe d’affectation dans la fenêtre ENREGISTRER, Valeurs prédites :
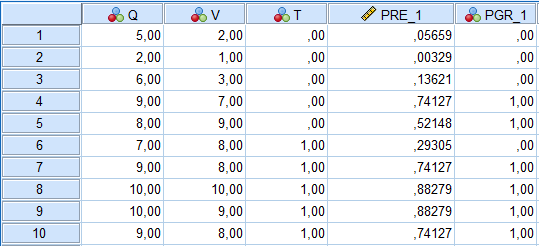
Nous pouvons voir à partir de la sortie que si un cas a une probabilité prédite (PRE_1) supérieure à 0,5, il est classé dans le groupe = 1 (PGR_1 est la désignation du groupe prédit). S’il a une probabilité prédite inférieure à 0,5, il est classé dans le groupe = 0. Notez que ces probabilités prédites concordent avec les résultats de classification générés plus tôt dans notre tableau de classification :
-
Pour ceux du groupe = 0, 3 cas sur 5 ont été correctement classés, soit 60 %.
-
Pour ceux du groupe = 1, 4 cas sur 5 ont été correctement classés, soit 80 %.
Une régression logistique a été effectuée sur la variable dépendante de formation (0 = aucune, 1 = programme de formation) pour savoir si le score quantitatif (Q) peut être utilisé pour prédire l’appartenance au groupe. Q n’a pas été trouvé comme un prédicteur statistiquement significatif (p = 0,120), bien que cela soit probablement dû à une puissance insuffisante. La classification utilisant Q a augmenté à 70 %. Le R² de Cox & Snell a été rapporté à 0,401, et le R² de Nagelkerke était égal à 0,534. En exponenciant le logit, il a été constaté que pour une augmentation d’une unité de Q, les cotes d’être classé dans le groupe 1 par rapport au groupe 0 étaient de 2,63.
Comme dans la régression des moindres carrés ordinaires, on peut également évaluer un modèle de régression logistique ajusté pour les valeurs aberrantes et d’autres points influents dans le même esprit que pour les modèles de régression linéaire et effectuer des analyses de résidus, bien que nous ne le fassions pas ici. Pour plus de détails, voir l’excellent traitement de Fox (Fox 2016) de ces questions telles qu’elles se rapportent spécifiquement à la régression logistique et aux modèles linéaires généralisés.