Nous avons mentionné que les carrés moyens représentent une sorte de moyenne pour chaque source de variation, celle de l’enseignement et celle de l’erreur. Nous pouvons en dire un peu plus sur les carrés moyens : ce sont, en réalité, des variances. Ainsi, nous avons une variance (valeur MS) pour l’enseignement et une variance (valeur MS) pour l’erreur. Avec ces deux variances en main, nous pouvons maintenant expliquer la logique du test F pour l’ANOVA.
Sous l’hypothèse nulle de moyennes de population égales, nous nous attendrions à ce que MS enseignement soit à peu près égal à MS erreur. Autrement dit, si nous générons un ratio de MS enseignement sur MS erreur, nous nous attendrions, sous l’hypothèse nulle, à ce que ce ratio soit approximativement égal à 1,0.
Sous l’hypothèse nulle H0:μ1=μ2=μ3=μ4, nous nous attendrions à ce que le ratio MS enseignement sur MS erreur soit approximativement égal à 1,0. Si l’hypothèse nulle est fausse, nous nous attendrions à ce que MS enseignement soit plus grand que MS erreur, et donc que le ratio résultant soit supérieur à 1,0.
Lorsque nous calculons le ratio F pour nos données, nous obtenons MS enseignement/MS erreur = 588,042/18,842 = 31,210. Autrement dit, notre statistique F obtenue est égale à 31,210, ce qui est bien plus élevé que ce à quoi nous nous attendrions sous l’hypothèse nulle d’absence de différences entre les moyennes (rappelons que cette attente était d’environ 1,0). La question que nous nous posons maintenant, comme dans pratiquement tous les tests de signification, est la suivante : Quelle est la probabilité d’observer une statistique F comme celle-ci ou plus extrême sous l’hypothèse nulle ? Si cette probabilité est très faible, cela suggère qu’une telle valeur de F est très improbable sous l’hypothèse nulle. Par conséquent, nous pouvons décider de rejeter l’hypothèse nulle et d’inférer une hypothèse alternative selon laquelle, parmi les moyennes de population, il existe une différence quelque part.
La valeur p pour notre ratio F est indiquée comme étant égale à 0,000. Elle n’est pas réellement égale à zéro, et si nous cliquons sur le nombre 0,000 dans SPSS, cela révèlera la valeur exacte :
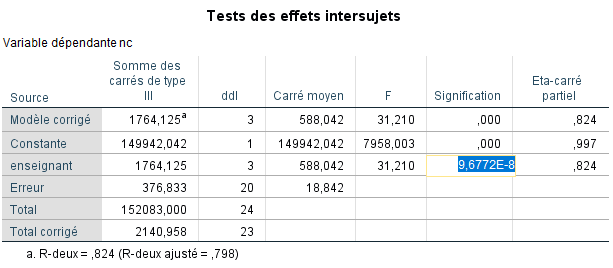
Nous notons que la valeur p est égale à 9,6772E-8, ce qui correspond à 0,000000096772, ce qui est statistiquement significatif pour p<0,05, 0,001, etc. Par conséquent, nous avons des preuves pour rejeter l’hypothèse nulle et pouvons inférer l’hypothèse alternative selon laquelle, parmi les moyennes de population, il existe une différence quelque part. Nous ne savons pas immédiatement où se trouve cette différence, mais nous avons des preuves via notre ratio F qu’une telle différence entre les moyennes existe quelque part.